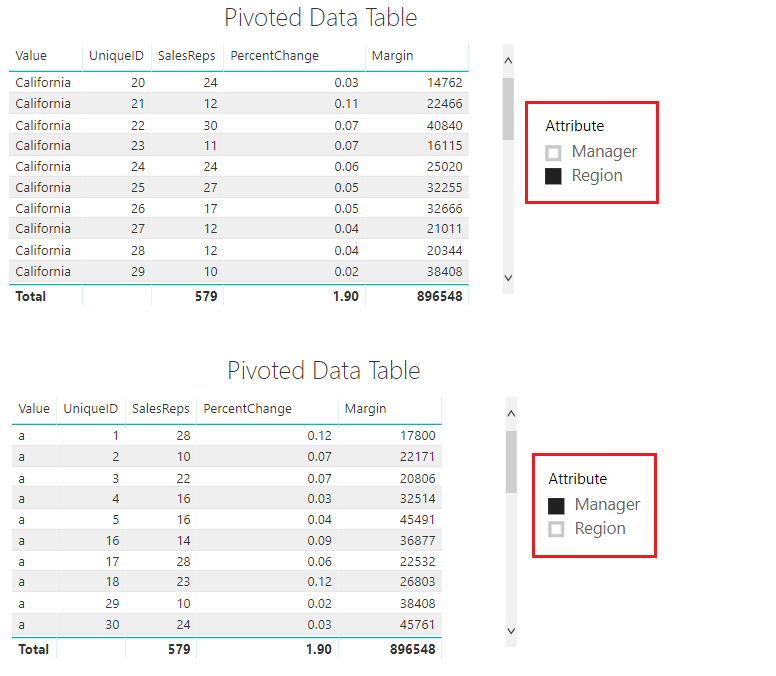
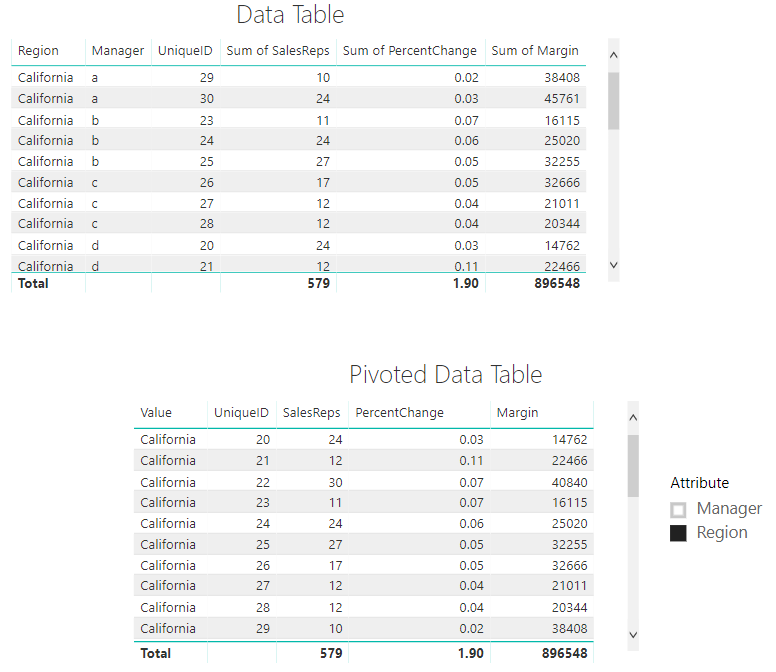
Of all the connection types, I’ve always gravitated towards this one. I imagine it is because I come from the database developer side of things. I’m a big fan of doing things one time, and having one version that controls many reports is extremely appealing. In fact, this topic was my first blog on Power BI so long ago (here for those feeling nostalgic). The live connection is the most powerful of all the connections that Power BI has to offer in my opinion.
Before we dive into the deep stuff, are you aware that you can use this connection type without your own instance of Analysis Services? Let me explain. Anyone who uses the “Power BI Service” connector that was first made available in April 2017 and released to GA in August 2017 is using a live connection to an Analysis Services Instance hosted in in your Power BI tenant. In fact, each time you build a Power BI report in the Desktop, you are building a Tabular model that is then created in the cloud upon publish! This live connection method allows you to gain a bit more control. You can deploy a single dataset to the Service and re-use it to build multiple reports! Having your own instance of Analysis Services on premises or Azure lets you maximize your development and deployment efforts and truly create a sustainable reporting solution.
The evolution of a Power BI solution “should” typically land in a space where a centralized or several centralized models are being used as the backbone for the vast majority of Power BI reports. This centralized approach is imperative in order for large scale BI initiatives to be successful. SQL Server Analysis Services Tabular is the typical implementation that I see most often employed due to the relational nature, compression, in memory storage and speed. That being said, lets dive into the details of what a centralized model gives us, and the pros & cons of the Power BI Live Connection.
Cons:
-
Most limiting of all in terms of disabling Power BI features.
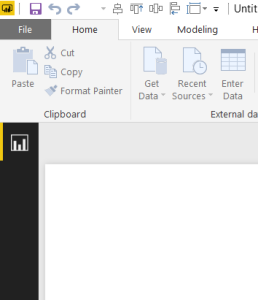
Notice: the Data and Relationships icons are not visible after making a Live Connection.
This is without a doubt the most intimidating to the end user that isn’t familiar with the live connection. As with Direct Query, there are features and capabilities in the Power BI Desktop that are just flat out turned off or completely gone. ETL / M / Query Editor? Gone. Data pane, DAX tables, Calculated columns? Gone. Power BI has become only the front end of the process. The expectation is that you are doing all the data mashup / ETL and modeling behind the scenes and as such, these features are all removed.
However, a really great addition in the May 2017 Desktop release was the addition of allowing measures to be created on top of the live connection. This means that if you have a couple measures you need to add to a single report, you can easily add those in the Power BI Desktop without the need to have them added to the model.
-
Cost
Without a doubt one of the most appealing aspects of Power BI is the price. It is amazing the amount of power and value you get for $10/month. (Desktop is free, but let’s just call it $10 because you need a Pro license to share). When you scale up and start to use enterprise level tools you need to look at the costs that those include. This post won’t go into details because there is a myriad of options out there and the number of options increase exponentially when you start comparing Azure to on-premises. Suffice to say, you’re looking at a much heftier investment regardless.
-
Different Tools
Another drawback to this connection is that we are now pulled out of the Desktop as a standalone solution and thrown into development areas. At bare minimum we’ll most likely be using Visual Studio, Team Foundation Server for version control, possibly SSIS, SQL Databases and SSAS. Throw in Azure and you might be using Azure SQL Data Warehouse with Azure Data Factory and Azure Analysis Services…
Pros:
-
Change Control
This feature that can be implemented by Team Foundation Services allows for a developer to manage their code. In the context of the model, this means that I can check in/check out and historically track all the changes to the model. Which in turn allows me to roll back to a previous version, control who has access to the model and secure the access to the model to a known group.
-
Central model that supports many reports
Hands down the benefit to the model / live connection is that I can build a central model that supports a vast number of reports. This streamlines development, lowers the time to implement changes across all reports from IT and centralizes calculations so that all parties are using the same metrics.
-
No memory or size constraints in Power BI
Another great feature is that a dedicated server / Azure implementation has the capability to scale up to whatever RAM is necessary to support the model. The limitations of the Desktop are gone, and Power BI capable of handling insanely high volumes of data. This is because the heavy lifting is happening behind the scenes. A prime example of this the new MSFT demonstration that uses 10 billion rows of data related to NY taxis. (Did you catch that? That is a “B” for “BILLION”) I saw it for the first time at PASS Summit 2017, but you can see a quick demo of that below, or here in the first portion of this scale up & diagnostic video.
Now, the underlying hardware in Azure must be immense for this to contain the 9TB of data, but I still think it is amazing that Power BI can provide the same drag and drop experience with quick interaction on a dataset that large. Simply amazing.
-
More Secure & Better security
Along with the security of being permissioned to access the model there is an extremely valid argument related to security that just make a SSAS model better. The argument is that while the functionality exists in the Power BI Desktop to enable row level security, the vast majority of the time, the report author shouldn’t control access to certain sensitive information. Having that live in a file accessible by others to be modified isn’t something that passes muster in most orgs. With a model that has limited access, change control and tracking, and process for deployment the idea that a DAX function controlling a security access level to information becomes more palatable.
-
Partitions
This feature enters stage left and it is just “Awesome”. Partitions in a model allow you to process, or NOT process, certain parts of the model independently from one another. This gives an immense amount of flexibility in a large-scale solution and make the overall processing more efficient. Using partitions allows you to only process the information that changes and thus reduce the number of resources, reduce processing, and create an efficient model.
All in all, a lot of this article was about model options behind the scenes, but effectively this is the core of the Live Connection. It is all the underlying Enterprise level tools that are required to effectively use the live connection against a SSAS instance. In some respects, I hope that this gives you some understanding of the complexity and toolsets that are actively being used when you are using Power BI in general. All these technologies are coupled together and streamlined to a clean user-friendly tool that provides its users with immense power and flexibility. I hope you enjoyed this series and that it brought some clarity around the different connection types within Power BI.
Thanks for reading! Be sure to follow me on Twitter and LinkedIn to keep up to date with Power BI related content.