Themes are the bedrock of consistency. As report authors it is important to create a consistent experience in a single, series or multitude of reports. With a little forethought you can easily build reports that exhibit the same fonts, properties and many other aspects with a Power BI Theme. If you aren’t using a theme and you build reports, its time you learn about them and put them into your arsenal.
Using Power BI Themes
Themes are available in a simple form in the Power BI Desktop and you can set color templates and some global properties for fonts and sizes. You can read more about that in Microsoft’s documentation here. However, themes go much, much deeper than that. You can set almost any visual property to a pre-configured setting. This greatly simplifies building a report, and creates a consistent experience across all your report pages. A single theme can be applied and removed from the Power BI desktop with ease.
Are Power BI Themes Hard to Build?
Creating a custom theme on your own would be hard… very hard. The theme files are built using the JSON format and have grown in complexity over the years. So, its highly unlikely that you are going to endeavor to build your own. Lucky for you, we love themes and created one of the first and most widely used theme generator to minimize the time it takes you to build a comprehensive theme to maximize your efforts. You can find and use that tool for free here. Another great resource has been provided by Matt Rudy, be sure to check out his Git repo. One of the key reminders when using themes: Make sure you don’t customize any properties in your report before applying a theme because they won’t be applied.
Discussion
We tackle all there is to know about implementation, when and how to best use themes and how to maximize your experience using themes in your Power BI reports in this episode. Be sure to join us to learn more.
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
First of all, go read this amazing blog put out by Alberto Ferrari over at SQLBI that he posted awhile ago. It is the context for the conversation we had and is well worth the read. 7 Reason DAX is Not Easy If you are new to DAX you will find a wealth of deep, insightful and helpful content in anything you find on SQLBI. Marco and Alberto are amazing guru’s in DAX and tabular models and have been perfecting their craft and helping the wider community hone their skills for many years.
I’m not going to re-hash the article as you should go read it yourself on their site. The points we talk about in depth in the podcast relate to focusing on the best methods to approaching and learning DAX. We take our experiences and the methods we learned and discuss at length the different points made in the article. Explore with us how you get better and overall simplify your process when building or troubleshooting DAX.
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
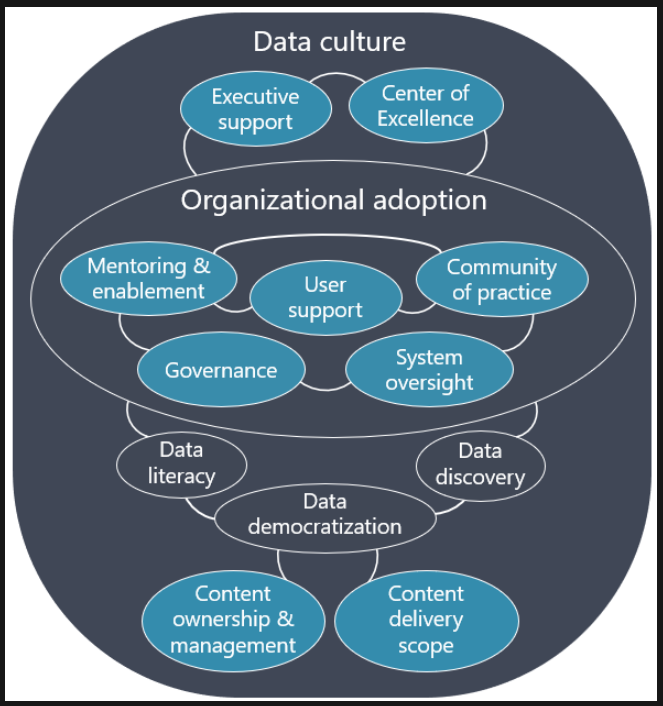
This month we partnered with the relaunch of the Des Moines user group to host Matthew Roche. This month’s topic is all about data culture. If you don’t know Matthew you should get to know him. His experience in developing enterprise data access is second to none. Along this journey of working with the largest Microsoft clients Matthew has learned a lot about their data cultures.
Obviously working with so many companies you can see what works and what does not. In this video webinar, Matthew discusses what is Data Culture. Additionally, there are aspects of what determines a successful environment.
Massive thank you to Matthew our presenter. Huge shout out to James Bartlett and Dipo Thompson for the planning. Be sure to follow our presenters on LinkedIn.
Matthew has also worked on many other impactful projects. One such project has been the Power BI Roadmap. This the best guide for individuals wanting to start their Power BI journey. On the Explicit Measures Podcast we discuss the Power BI roadmap quite often. Thus, we feel it adds a ton of value. Check it out for yourself.
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
This topic was gleaned from the absolute wealth of knowledge put down in the MSFT Power BI Adoption Roadmap. We highly recommend you check the full roadmap. In this episode, we focused in on Data Culture, this topic is a bit ambiguous as it relates to how you measure the outcome or success of your organizations data culture. Despite that, we took a good shot and covered quite a bit of ground and came up with some good ideas of how to better measure and determine how to build, how to measure and challenges organizations face when embarking on increasing the value of decision making based on data.
Its a Culture Thing
“You know it when you have it, and you know it went you don’t.” – Mike Carlo
“If you are trying to measure culture, you are really just trying to measure behavior.” – Tommy Puglia
“It’s pattern changing of people… one of the largest challenges any organization will have..” – Seth Bauer
How do you Measure it?
Behaviors are hard to measure, but you can put things in place to evaluate it. Tommy uses his sociology degree and brings up a good point in that there are ways in which we can directly and indirectly measure culture. Overall, the time invested in each of the different areas of the adoption roadmap will indicate how successful the data culture is. Success metrics are pointed out in how widely available data is to the organization.
Is it easy for individuals to find, access and use the right data at the right time? When they find it, do they know what it means? As organizations begin to invest time and resources in building out areas of the adoption roadmap the better and stronger they become at making data based decisions. The investments start to develop patterns of behavior that drive to better outcomes. Listen for more ideas on what sort of KPIs you could measure, or different patterns and behaviors would indicate your data culture is strong.
Listen to for these key points and more in our recent conversation
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
To say this another way. Not all columns have datatypes in DAX, specifically speaking to using dynamic ranking with an “Other” category. Let me explain.
The Tabular model is comprised of tables with typed columns. This is a truth learned in one’s Tabular infancy. Whether the table is imported, calculated, or Directly Queried does not matter; all tables have columns with explicitly defined types.
DAX is the language of the Tabular model. It has less type discipline than tables in the Tabular model. Measures can have a Variant data type. Implicit type conversions abound. Nor are DAX expressions limited to returning scalar values. DAX is a query language. An expression may return a table. When defining a table in DAX, projected columns have no explicit type. Each row’s value is calculated independently and its type depends on its value. This is the phenomenon we seek to explore in this post. If this seems unsurprising, you can probably stop here.
A practical scenario
Here is the scenario where I discovered this. I was helping a colleague with a dynamic ranking measure and aggregation. The requirement read:
Show the top for production plants as ranks 1 through 4. Group all others ranked 5 or lower together as “Other”.
We have three tables:
a fact table 'Fact'
a dimension table 'Dim', related to 'Fact' with the relationship 'Fact'[DimKey] <-N:1- 'Dim'[DimKey]
a disconnected table, 'Rank Selector', with the values: “1”, “2”, “3”, “4”, and “Other”.
We started with a measure [Agg] as our base measure.
Agg = SUM ( 'Fact'[Value] )
[_Rank (variant)] is a helper ranking measure, returning a rank 1-4 or “Other”.
_Rank (variant) =
VAR rawRank = RANKX ( ALL ( 'Dim' ), [Agg],, DESC )
// note this value is either a number 1-4 OR the string, "Other"
VAR groupedRank = IF ( rawRank <= 4, rawRank, "Other" )
RETURN
groupedRank
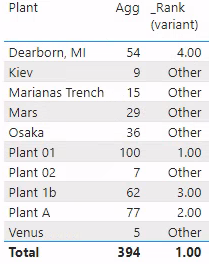
Below is a screengrab of these two measures evaluated against our 'Dim'[Plant]. As you can see, [Agg] returns a value for each plant. The top four plants have ranks of 1, 2, 3, and 4. The other plants all have the same rank, “Other”. This is all as expected.
'Dim'[Plant] with [Agg] and [_Rank (variant)] measures, working largely as expected. Each dim value has a value for [Agg] and a rank of 1-4 or the string, “Other”.
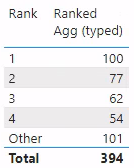
The issue reared its head when we attempted to use these ranks to define a new visual based on 'Rank Selector'[Rank]. We defined a measure to show [Agg] based on the plant’s rank (1-4 or “Other”), rather than the plant name. Note that 'Rank Selector'[Rank] is a column in a data model table, with Data type: Text. Our expectation is that we will see a table like the image below.
A table visualization showing six rows with labels: “1”, “2”, “3”, “4”, “Other”, and “Total”; and showing an aggregate alongside each.
Wherein our heroes encounter a challenge
[Ranked Agg (variant)] is the display measure to show aggregations against 'Rank Selector'[Rank]. We wrote the variant version you see below first, not realizing the perils that laid ahead. (Correct implementations follow later.)
Ranked Agg (variant) =
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (variant)],
"@val", [Agg]
)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
VAR result = SUMX ( currentRank, [@val] )
RETURN
result
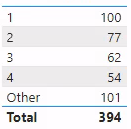
When we visualize this measure against 'Rank Selector'[Rank], we get the result below.
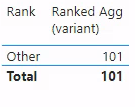
A table visualization showing only the 'Rank Selector'[Rank] value “Other” and “Total”. Specifically, we do not see any value for ranks “1”, “2”, “3”, or “4”.
A table visualization showing only the 'Rank Selector'[Rank] value “Other” and “Total”. Specifically, we do not see any value for ranks “1”, “2”, “3”, or “4”.
What is going on here? We see data only for the Rank Selector'[Rank] label “Other” but none of the numbers. Let us walk through the measure step-by-step to understand this result.
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
rankContext captures whatever the current filter context is for 'Rank Selector'[Rank]. This is one or a collection of the values: “1”, “2”, “3”, “4”, and “Other”. For a detail row of a table visualization, the context contains exactly one of those values. For a total row (assuming no other slicers or filters), the context contains all of those values.
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (variant)],
"@val", [Agg]
)
ranked is a table with all rows and columns of the data model table 'Dim' and two projected columns, [@rank] and [@val]. For any row, i.e., for any specific plant, [@rank] is one of 1-4 or “Other”. Many rows may have [@rank] = "Other". We do not expect ties, so there are exactly four rows with numeric ranks, one each for the ranks 1-4. (This table looks like the first table visualization screenshot above.)
The critical part of both the ranking logic and the phenomenon we are exploring is in currentRank. This is a subset of the table, ranked, holding only the row or rows which have a [@rank] value that exists in the filter context captured in rankContext (again, one or a collection of the values “1”, “2”, “3”, “4”, and “Other”).
Note, that we see data only for the Rank Selector'[Rank] label “Other”. As you recall, our [_Rank (variant)] seemed to work correctly above – it definitely returned ranks 1-4, not just “Other”. 'Rank Selector'[Rank] has the correct values. We checked that our logic in [Ranked Agg (variant)] was correct. We verified in DAX Studio that ranked held the correct table. We even got to the point that we checked whether VALUES was behaving as we expected in rankContext. (I will note that if you find yourself verifying the behavior of an expression as basic as VALUES ( 'Rank Selector'[Rank] ), then you, too, may find yourself questioning what has brought you to this point.)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
We continued checking and troubleshooting and identified that currentRank had binary state: either it would be an empty table or it would be a table holding only rows with [@rank] values of “Other”. It would never hold a row with a rank value of 1, 2, 3, or 4. It seemed that the predicate in our FILTER would never find 1 to be equal to 1, or 2 equal to 2, and so on.
How could basic logic be so broken just in this measure? There was much gnashing of teeth. Several head-shaped indents were beaten into the nearest wall.
DAX, the language, has a more permissive type system than the Tabular model
You may have observed some apparent inconsistency in my quoting or not-quoting the rank values above. In fact, I have been scrupulous to always quote values when referring to 'Rank Selector'[Rank], the model column with type Text, and to not-quote the rank values returned from [_Rank (variant)]. The column 'Rank Selector'[Rank] has exclusively string values. The measure [_Rank (variant)] sometimes returns a numerically typed value in the range 1-4 and sometimes returns the string “Other”.
In DAX, 1 = 1 is an equality test that returns TRUE. Similarly, 1 IN {1, 2, 3, 4} returns TRUE, because 1 = 1 and 1 exists in the table there. In DAX, 1 = "1" is an equality test that throws a type error. Numbers cannot be tested for equality with strings. They are different types. Therefore, a number can never be equal to a string. Thus, 1 IN {"1", "2", "3", "4", "Other"} also throws a type error.
The lightbulb moment
In [Ranked Agg (variant)], currentRank has a column [@rank] with type Variant. Sometimes, [@rank] has a value in the range 1-4, type Whole Number. Sometimes it has the value “Other”, type Text. When we evaluate the predicate [@rank] IN rankContext, there are exactly two possible results. Either we ask for an impossible membership test, “Is this numerically typed rank value in the set of Text values?”, or we ask whether the string “Other” is in that set. The first cannot succeed. The second only succeeds for the “Other” rank.
The Fix
The fix, then, is straightforward. We must always return a value of type Text in our ranking measure. Correct measures are below with comments highlighting the modifications.
_Rank (typed) =
VAR rawRank = RANKX ( ALL ( 'Dim' ), [Agg],, DESC )
VAR groupedRank =
// with an explicit typecast, our measure now *always* returns a string-typed value
IF (
rawRank <= 4,
FORMAT ( rawRank, "0" ), // force string type
"Other"
)
RETURN
groupedRank
Ranked Agg (typed) =
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (typed)], // the only difference here is using our typed rank helper measure
"@val", [Agg]
)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
VAR result = SUMX ( currentRank, [@val] )
RETURN
result
The measures above give us the results we expected all along, as you can see in the table visualization below.
A table visualization showing 6 rows with labels: “1”, “2”, “3”, “4”, “Other”, and “Total”; and showing the correct values of [Ranked Agg (typed)] alongside.
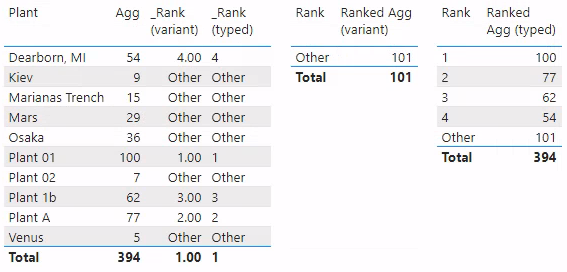
Below is a screengrab of all the measures in visualizations, so you can see the differences.
A screenshot with all three of the table visualizations shown prior in this post: the 'Dim'[Plant] table with [Agg], [_Rank (variant)], and [_Rank (typed)]; the incorrect behavior with [Ranked Agg (variant)]; and the correct behavior with [Ranked Agg (typed)].
Summary
Tabular model tables have columns of explicit type. DAX expressions have implicit types. Columns defined in DAX have Variant type. Each row has an implicit type based on its value. If such a column is a Calculated Column added to a data model table, then an explicit type must be assigned and all values in that column will be cast to that type at load time. When such a column is used as an intermediate step in some calculation, each row may have a different type. If your operations depend on types, you must account for this explicitly. This is especially relevant when operating on data model and DAX tables together.
Insights from the community
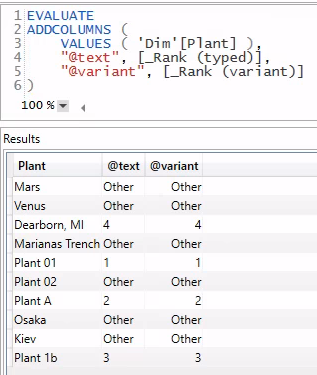
When talking about this with some peers, Maxim Zelensky (blog, Twitter) observed that there is no type indication in Power BI Desktop. Nevertheless, you can identify this sort of thing in DAX Studio. The result of a query such as that below will right-align Variant-typed values and left-align Text-typed values. This query references the included Power BI file and its results are shown in a screenshot below. You can observe similar alignment in the table visual shown above. In general, when visualized, numeric data is presented with right-alignment and textual data left-aligned. This practice predates Power BI; it is a general rule that Power BI and DAX Studio wisely adopted.
A screenshot showing the results of the above query, with [@text] left-aligned and [@variant] right-aligned.
Using the sample code and PBIX
Here is a link to download the PBIX that was used for examples above. This has four visuals to demonstrate the phenomenon discussed in this blog post. The first visual is a table with 'Dim'[Plant], [Agg], [_Rank (variant)], and [_Rank (typed)]. Of note in the first visual is left-vs-right alignment of the two [_Rank ...] measures. The second visual is a table with 'Rank Selector'[Rank] and [Ranked Agg (variant)], showing the incorrect results of the measure depending on a Variant-typed intermediate column, with a value only for rank “Other”. The third visual contrasts with the second, using [Ranked Agg (typed)] to show the correct behavior of the dynamic ranking and grouping logic, with a value for all ranks and a correct total. Lest one protest that the phenomenon above may be an artifact of using VARs, the last visual, on the bottom, shows an example that uses no VARs and references no other measures. The behavior of this last visual is identical to the incorrect [Ranked Agg (variant)] version.
Trolling… we should clear up the definition of this right off the bat. We aren’t talking about the type of trolling where we spend a bunch of time finding things on the Power BI Ideas site and say obnoxious things about them to elicit a response. We may say obnoxious things, but not in that context. In any case, what we spend time doing periodically is seeing what fantastic ideas people are coming up with and requesting for future feature enhancement. Today we’re going to dive into some of our favorites and would encourage you to give them a look. If you agree with us, be sure to vote them up!
The Power BI Ideas Site
If you aren’t familiar this site was created right alongside the Power BI Community site and has been part of the ecosystem of Power BI for a long time. It certainly speaks to Microsoft wanting to hear from, and build a great community around Power BI right from launch. The site is a direct way that users can submit ideas, garner support from the community, and raise the visibility of that request. The Power BI product teams then review the most voted on requests and determine if the request is something that they want to add into the tool.
Trolling & Contributing
Perusing the ideas and contributions of others is always a good way to broaden your scope. It gives you a taste of what other people need and want in a tool that may serve you just fine. Its also a shortcut to understand what isn’t in the tool that maybe you thought was. More importantly though, the site is a great way to contribute your ideas to making Power BI even better than it is already. We encourage everyone to contribute.
Recommend that MSFT keep the Idea status’s up to date
Join us for the full conversation as we discussed all these and more in the podcast!
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.