Alex Powers is a staple in the Power BI community. Especially when it comes to working with Power Query. We had a super fun time unpacking all the rich features of Power Query with Alex in this series.
📋 Playlist Summary
Alex Powers joins Power BI Tips to explore advanced techniques and essential skills in Power Query, aimed at maximizing performance and deepening understanding of this data engineering tool.
The Milwaukee Crew is back at it again with the October 2020 Power BI User Group (PUG). This month we have the amazing Gil Raviv talk to us about Power Query and the Enterprise. For those of you who don’t know Gil he is a superb Power Query Expert.
Gil talks to about Power Query in different enterprise domains. Learn which tools to use and which ones are not quite ready for prime time. You will learn a ton in this great session.
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
In the October 2020 release of Power BI desktop you have the ability to load a dataset from the splash page. For this tutorial we dig in on how Microsoft enables a default dataset. Additionally we show you how to customize the default dataset for your needs.
Quite often I need to prototype a visual, or work on some sample data to design a report. The very first step is always loading some sample data. Now that Power BI desktop comes with a default dataset, we leverage this feature to speed up our development process.
Watch the YouTube Video
Additional Thoughts
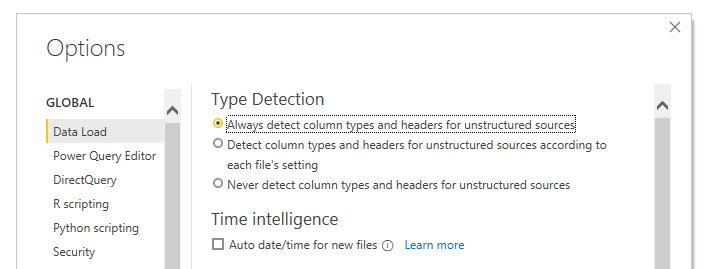
In this video I explain that the dataset does not auto load with datatypes enabled. This was due to my default setting within Power BI desktop. If you’d like you can make Power BI Desktop auto detect your datatypes for you.
This setting can be changed by the following steps:
Click on the File button
In the drop down menu, Click on the Options and Settings
In the menu on the right Click the button labeled Options
Under the Global section in the Options menu Select the item labeled Data Load
Change the Type Detection for loading data
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
This article is the second part in a series on API calls. It will look at some best practices and considerations when using API calls in Power Query. While it does not serve as a definitive list, it is an important start to consider performance when using such queries.
The articles in the first part of the series can be read here:
Batch queries refer to sending information in “batches”. Making an API call requires information to be sent to an external source, that information returned, then the information parsed and then loaded. Imagine we are doing this for thousands of different dimensions. Consequently, you will have the exact same process to be repeated this many times. Instead, check in the API documentation if batch queries are available. As a result, you may be able to send many of the dimensions in the same API call. This will drastically reduce the amount of times this process happens.
Use Data Factory
Data Factory is an Azure service that offers no/low code solution to Extract, Transform and Load (ETL) or ELT (Extract Load, Transform) processes. These are called “pipelines”. Pipelines are repeatable processes that allow you to copy and move data from one source to another (read the documentation here).
Let’s say you’re trying to load a high level of stock data for thousands of stocks. By doing this in Power Query may put big stress on your gateway. Your gateway may get overloaded and cannot handle sending so many complex API calls. It may be a better idea to load the data into a separate table (such as Azure Synapse). Then your power BI report can read this file directly. Read this documentation for a good overview of this architecture.
Shifting this to the Azure cloud can leverage Data Factory’s auto-scalability and ability to handle large volumes of data. This results in a more reliable and robust process.
Consider the most efficient design
Always consider the way that will send the least number of queries. For example, if you are using historical data that doesn’t change, think if you need to refresh this data every day. In addition, try and avoid sending the same information multiple times. Do queries off unique lists.
Only return the correct data
If you load data into Power Query from a source such as SQL Server and then remove columns, a process called Query Folding will take place. Essentially, the data isn’t even loaded into Power Query – it edits the SQL query to not include these columns.
This can only be done on certain sources. Custom APIs will not do this. Therefore, make sure you send the correct queries. Don’t return extra bits of data that is not needed and make sure you only return columns you will use.
Review
While this is by no way a definitive list, it should serve as a starting point to acknowledge performance considerations. Pay attention to how many queries are sent out and try to limit duplication. Remember, Power Query is a powerful tool, but make sure you are using the right tool for the job. Very large and complex operations can be improved with the help of other tools, such as Data Factory.
In October of 2019 Power BI released a new file type, PBIDS. The Power BI Desktop Source (PBIDS) file is a JSON object file that aids users connecting to data sources. In true PowerBI.Tips fashion we have of course, made a tool for that.
Introducing Connections
Today we release the new tool called Connections. It can be found at https://connections.powerbi.tips/ . With this tool you can use our predefined templates or customize one of your own file. To learn more about this sweet sweet JSON editing tool check out the following YouTube Video:
Technical Details
For more information on the Power BI Desktop Source file check out these links:
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
As report authors we sometimes get caught up in how easy it is to create a report and provide value to the business. Each report is an opportunity to make a big contribution to the organization. Power BI makes it easier than ever to turn many of those reports around quickly. This is a good thing of course. But, sometimes we can get caught up in the madness of turning out another report with only a flash of recall that we could have used the same or similar model done in a different report. The internal monologue kicks in.
“Pffft! Re-use a model, that is way to much work! Why do that?, when we can just create a copy of the PBIX (Desktop file) and have two models to manage with the two reports for the same business area! That sounds like fun!”
Hmm… Or does this actually sound awfully similar to the challenges one might face with sprawling Excel solution. Where variants of logic are buried in different files. Only the composer knows how to bring order from the chaos. Might I suggest that we spare ourselves that sort of pain. Just learn how we can easily leverage our already hard fought model work. Avoid tedious updates without having to over complicate our nirvana of sticking to the business world, but how would we do that?
The Answer
Power BI datasets. Power BI datasets allow us to re-use our model across multiple reports. This simplifies and speeds up future report authoring. Also this gives us the building blocks for sharing that dataset to a wider audience.
How do we create one?
Technically, we’ve likely already created many. You see, when we publish a Power BI report, we publish a dataset along with it. This dataset is stored in the Power BI Service, and our deployed report relies on it now. But the connector “Power BI datasets” allows us to connect directly to any of these datasets that we have permission to edit. This means that we have the ability to extend a single model across multiple reports without the need of standing up a separate Analysis Services server anywhere. This is a big deal, this allows the everyday business user to leverage a reusable model. A single change or update to a calculation can update multiple reports at the same time. One measure or calculation addition can be done in one place instead of many.
All we need to do to create a dataset that we can connect to is publish a PBIX file that contains data. I’ve adopted a practice recently and rather than generating my first report and reusing that model, I now upload a PBIX file that ONLY contains the model and I name it something like “Sales-Model”. Now I have an object that I’ll know serves the purpose of just being a model instead of a report. This makes it easier from a trace-ability standpoint when looking at the related objects in the Service or selecting it from my list of options when choosing my dataset.
How do we use one?
Using the Power BI dataset is one of the most
straightforward connections in Power BI. Selecting Get Data -> “Power BI
datasets”
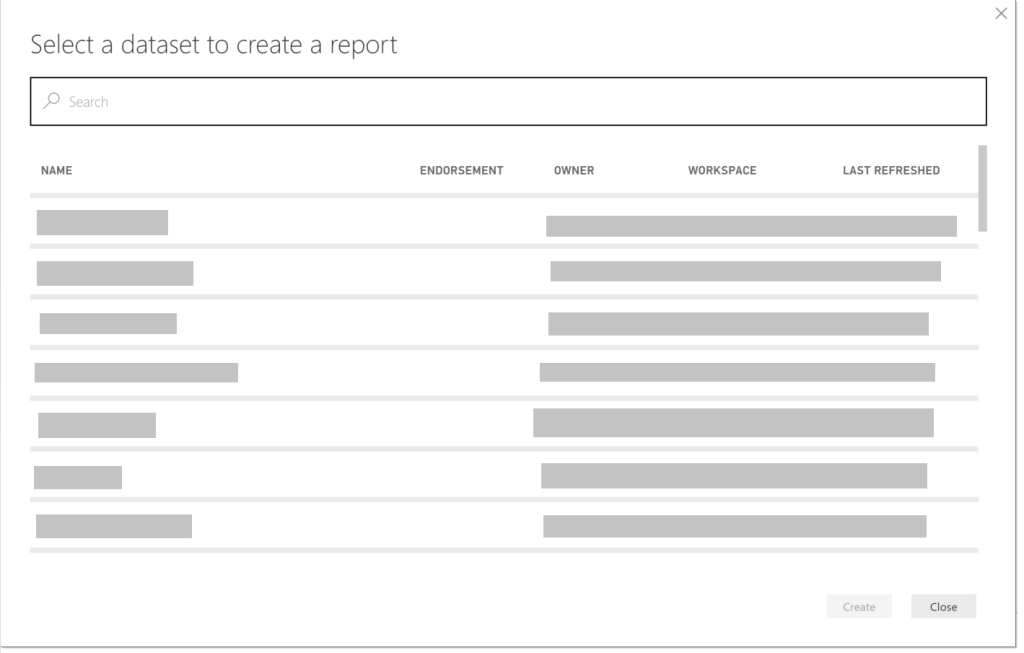
This brings up the menu of all the datasets in the Power BI Service. The list that is shown are the datasets that our user account has access to use. The great thing about these datasets are we now have the ability to connect to and use a dataset from a different workspace provided we have permissions to edit them. This feature is called a Shared Dataset. Select the dataset and your report is automatically connected to dataset.
Now, what we’ll notice here is that using this feature automatically pulls in a model for us and we can start building our report. This data source connection behaves exactly the same as if we created our own “live” connection to an Analysis Services instance we would set up. Probably not shocking to any reader here. But, that is exactly what is happening in this case as well. We get the benefit of Microsoft handling all that painful work for us while we reap the benefits of a streamlined process.
As with any “easy button” solution, there are pro’s and con’s. What I mean is that in our new reports we do have easy access to the model. Now you can start building reports immediately. We don’t have the ability to modify the model or the ETL processes. If we want to edit then we need to go back to the original dataset to make those changes.
But the minor inconvenience of having 2 PBIX files open if we need to in order to make updates to the model is trivial compared to being able to connect many reports to that single model. The live connection does still allow the report author the ability to create measures. So, if there are measures that are only suited to our report and not the overall model we still have the ability to add them.
Once we’ve completed
our report, we just publish as we normally would, only this time the dataset is
already out in the Service and only our report is published. There are so many
things we can now do to share that dataset, but we’ll leave that to another
article.
If you’ve never used this method before, I would highly encourage you to try it out. Any time you can save yourself now with reducing the number of models you maintain, the faster you can produce more reports. You now spend less time maintaining all the reports you are publishing.
Happy report building!
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
Of all the connection types, I’ve always gravitated towards this one. I imagine it is because I come from the database developer side of things. I’m a big fan of doing things one time, and having one version that controls many reports is extremely appealing. In fact, this topic was my first blog on Power BI so long ago (here for those feeling nostalgic). The live connection is the most powerful of all the connections that Power BI has to offer in my opinion.
Before we dive into the deep stuff, are you aware that you can use this connection type without your own instance of Analysis Services? Let me explain. Anyone who uses the “Power BI Service” connector that was first made available in April 2017 and released to GA in August 2017 is using a live connection to an Analysis Services Instance hosted in in your Power BI tenant. In fact, each time you build a Power BI report in the Desktop, you are building a Tabular model that is then created in the cloud upon publish! This live connection method allows you to gain a bit more control. You can deploy a single dataset to the Service and re-use it to build multiple reports! Having your own instance of Analysis Services on premises or Azure lets you maximize your development and deployment efforts and truly create a sustainable reporting solution.
The evolution of a Power BI solution “should” typically land in a space where a centralized or several centralized models are being used as the backbone for the vast majority of Power BI reports. This centralized approach is imperative in order for large scale BI initiatives to be successful. SQL Server Analysis Services Tabular is the typical implementation that I see most often employed due to the relational nature, compression, in memory storage and speed. That being said, lets dive into the details of what a centralized model gives us, and the pros & cons of the Power BI Live Connection.
Cons:
Most limiting of all in terms of disabling Power BI features.
Desktop Live Connection
Notice: the Data and Relationships icons are not visible after making a Live Connection.
This is without a doubt the most intimidating to the end user that isn’t familiar with the live connection. As with Direct Query, there are features and capabilities in the Power BI Desktop that are just flat out turned off or completely gone. ETL / M / Query Editor? Gone. Data pane, DAX tables, Calculated columns? Gone. Power BI has become only the front end of the process. The expectation is that you are doing all the data mashup / ETL and modeling behind the scenes and as such, these features are all removed.
However, a really great addition in the May 2017 Desktop release was the addition of allowing measures to be created on top of the live connection. This means that if you have a couple measures you need to add to a single report, you can easily add those in the Power BI Desktop without the need to have them added to the model.
Cost
Without a doubt one of the most appealing aspects of Power BI is the price. It is amazing the amount of power and value you get for $10/month. (Desktop is free, but let’s just call it $10 because you need a Pro license to share). When you scale up and start to use enterprise level tools you need to look at the costs that those include. This post won’t go into details because there is a myriad of options out there and the number of options increase exponentially when you start comparing Azure to on-premises. Suffice to say, you’re looking at a much heftier investment regardless.
Different Tools
Another drawback to this connection is that we are now pulled out of the Desktop as a standalone solution and thrown into development areas. At bare minimum we’ll most likely be using Visual Studio, Team Foundation Server for version control, possibly SSIS, SQL Databases and SSAS. Throw in Azure and you might be using Azure SQL Data Warehouse with Azure Data Factory and Azure Analysis Services…
Pros:
Change Control
This feature that can be implemented by Team Foundation Services allows for a developer to manage their code. In the context of the model, this means that I can check in/check out and historically track all the changes to the model. Which in turn allows me to roll back to a previous version, control who has access to the model and secure the access to the model to a known group.
Central model that supports many reports
Hands down the benefit to the model / live connection is that I can build a central model that supports a vast number of reports. This streamlines development, lowers the time to implement changes across all reports from IT and centralizes calculations so that all parties are using the same metrics.
No memory or size constraints in Power BI
Another great feature is that a dedicated server / Azure implementation has the capability to scale up to whatever RAM is necessary to support the model. The limitations of the Desktop are gone, and Power BI capable of handling insanely high volumes of data. This is because the heavy lifting is happening behind the scenes. A prime example of this the new MSFT demonstration that uses 10 billion rows of data related to NY taxis. (Did you catch that? That is a “B” for “BILLION”) I saw it for the first time at PASS Summit 2017, but you can see a quick demo of that below, or here in the first portion of this scale up & diagnostic video.
Now, the underlying hardware in Azure must be immense for this to contain the 9TB of data, but I still think it is amazing that Power BI can provide the same drag and drop experience with quick interaction on a dataset that large. Simply amazing.
More Secure & Better security
Along with the security of being permissioned to access the model there is an extremely valid argument related to security that just make a SSAS model better. The argument is that while the functionality exists in the Power BI Desktop to enable row level security, the vast majority of the time, the report author shouldn’t control access to certain sensitive information. Having that live in a file accessible by others to be modified isn’t something that passes muster in most orgs. With a model that has limited access, change control and tracking, and process for deployment the idea that a DAX function controlling a security access level to information becomes more palatable.
Partitions
This feature enters stage left and it is just “Awesome”. Partitions in a model allow you to process, or NOT process, certain parts of the model independently from one another. This gives an immense amount of flexibility in a large-scale solution and make the overall processing more efficient. Using partitions allows you to only process the information that changes and thus reduce the number of resources, reduce processing, and create an efficient model.
All in all, a lot of this article was about model options behind the scenes, but effectively this is the core of the Live Connection. It is all the underlying Enterprise level tools that are required to effectively use the live connection against a SSAS instance. In some respects, I hope that this gives you some understanding of the complexity and toolsets that are actively being used when you are using Power BI in general. All these technologies are coupled together and streamlined to a clean user-friendly tool that provides its users with immense power and flexibility. I hope you enjoyed this series and that it brought some clarity around the different connection types within Power BI.
Thanks for reading! Be sure to follow me on Twitter and LinkedIn to keep up to date with Power BI related content.
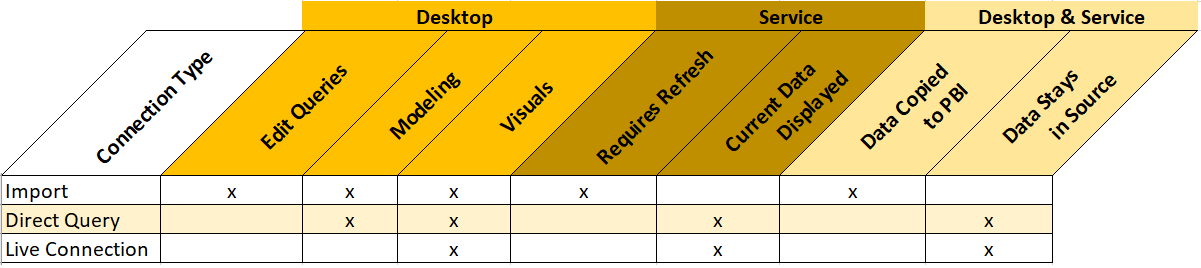
Now that we’ve solidly gotten through the basics in terms of what connection types are in the opening blog, found here, and detailed out what is included in the default connection type of Import found here, let’s get on with some of the more interesting connections.
Connection Type Outline
Direct Query is the first connection type that we will discuss that extends, but at the same time limits functionality in the tool itself. In terms of data access this connection type allows us to access our data in the source system. The supported data sources for direct query can be found here. This is distinctly different than what we observed in the import method. When using Import, the data is a snapshot and refreshed on a periodic basis, but with Direct Query it is live. “Live” means that with Direct Query the data stays in the source system and Power BI sends queries to the source system to return only the data it needs in order to display the visualizations properly. There are some pros and cons in using this connection so it is important to understand when you might use it, and when you should probably avoid this connection.
Cons:
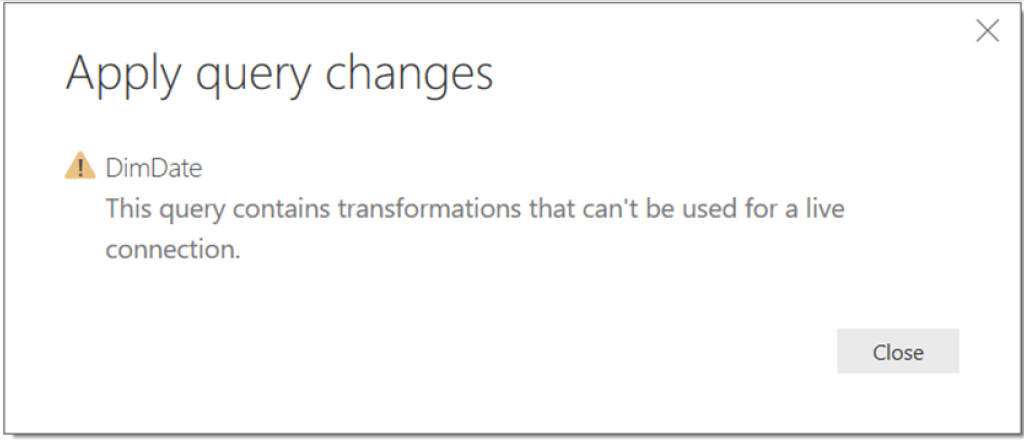
When Direct Query is used you can no longer do many of the data mashup actions in the “Edit Queries” section of Power BI. It is assumed that you will have already done this in the backend. You can do simple actions such as removing columns, but don’t expect to be able to manipulate the data much. The Query Editor will allow you to make transformations, but when you try to load to the model you will most likely get an error that looks something like this
Direct Query Error
The data tab is also disabled in the model layer and thus you need to make sure that all the formatting and data transformations are completed in the source.
Data Tab No Longer Present
You can do some minor adjustments to format, but this could be a heavy restriction if you don’t have access to the data source.
There are performance impacts to the report that need to be taken into consideration. How large is the audience that will be interacting with the report? How busy is the source system, are there other processes that could be impacted?
Troubleshooting skills in source system language
Multiple applications required to adjust data ingestion and formatting
Pros:
The Direct Query connection does not store any data. It constantly sends queries to the source to display the visuals with the appropriate filter contexts selected.
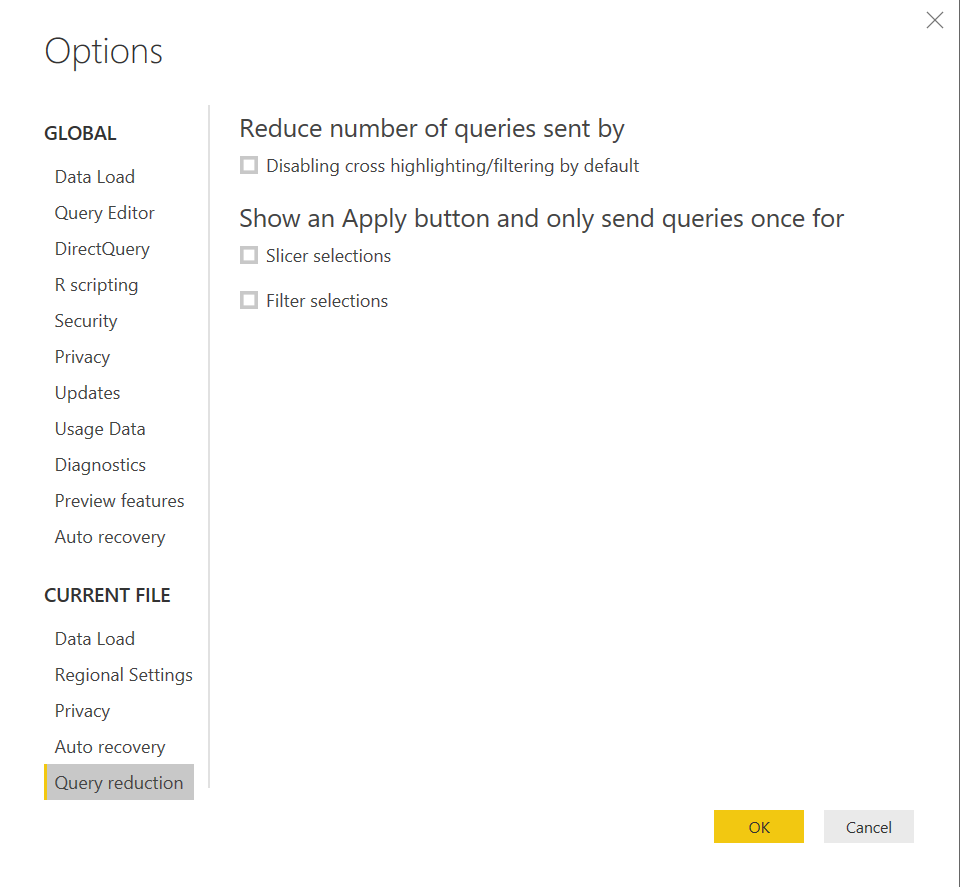
In the November 2017 release there is a new capability in Power BI allows you to reduce the traffic and enhance this connection method exponentially. The feature is called Query reduction, and allows you to enable an “apply” button on a slicer or filter. The benefit with this option is that you can set all your selections of a filter prior to Power BI executing the query. Before this feature was available, every selection you made would fire off a query to the source database. To enable this feature, go to File -> Options and Settings -> Options -> Query Reduction you will find these options to help with Direct Query Performance.
Query Reduction Options
Note: This enhancement greatly increases the performance of a Power BI report against the data source, but be aware that there could be poor query performance, or aspects of the solution that would require troubleshooting in the data source depending on what queries are being passed. This would require understanding of how to performance tune the source.
Deployment of the Direct Query connection requires the use of the gateway previously called the Enterprise Gateway. Note that the Enterprise Gateway is different than the personal Gateway.
No data is ingested into the model using Direct Query thus, there is no need to schedule a refresh. Once the dataset is connected to the Gateway, the data source feeds information to the report as the user interacts with the report.
It will always show the latest information when you are interacting with the report.
Direct Query is a powerful connection type in that it produces the most up to date data. However, as we have seen, it does come with some considerations that need to be taken into account. The Pros and Cons of the connection mostly revolve around whether or not the end user can understand and deal with potential performance issues, updating data retrieval processes, and understand the downstream implications of a wider audience. Typically, Direct Query is used in extremely large datasets, or in reports that require the most up to date information. It will most likely always perform slower than an import connection and requires an understanding of tuning and troubleshooting of the data source to alleviate any performance issues.
Power BI’s default connection type is Import. In fact, if you have never dealt with a data source that handles multiple loading methods, you may never know that there are different loading methods because Power BI automatically connects via import. However, if you’ve ever worked with sourcing information from databases or models, then you have seen the option to select Import vs. Direct Query or Live Connection.
Note: This is a continuation of the Power BI Connections series. If you would like to read the overview of all the Power BI Connection types you can do so here.
Below is a quick chart to outline some of the considerations to help you decide whether import is right for you.
Connection Type Outline
Import is the only connection type that brings to bear the full capabilities of the Power BI Desktop. As you move from Import to Direct Query to Live Connection, you trade off ease of use for solutions that will scale.
Import will pull in the data from the data sources that you have connected to and store & compress the data within the PBIX file. The eventual publishing of the PBIX file will push the data to Azure services supported in the Power BI Backend. For more information on data movement and storage see the Power BI Security Whitepaper.
When using import, the full Edit Queries suite is available to mash up any data source, transform data-sets and manipulate the data in any way you see fit.
Query Editor
Once you click Close & Apply, the data is loaded into the “front end” of Power BI into the Vertipaq engine.
Note: The Vertipaq engine is used in both Excel and SQL Server Analysis Services Tabular models. In simple terms, it is the backbone that compresses all your data to make it perform extremely fast when visualizing, and slicing & dicing. For more detailed information on the engine see an excerpt from Marco Russo & Alberto Ferrari’s book “The Definitive Guide to DAX: Business intelligence with Microsoft Excel, SQL Server Analysis Services, and Power BI” found here.
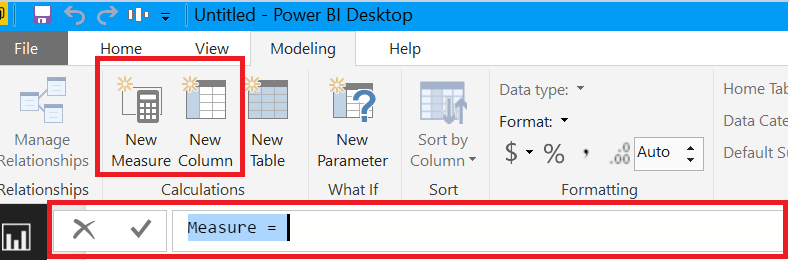
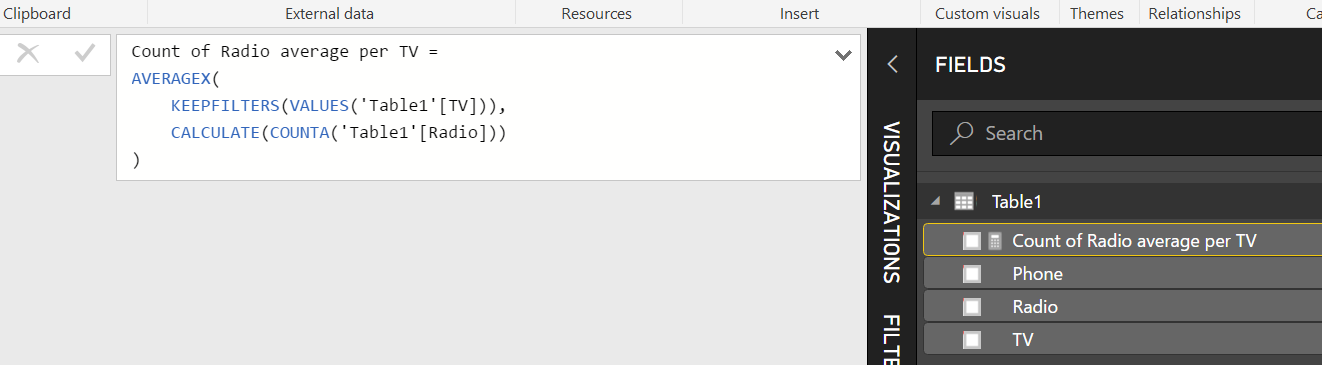
At this point it is ready for you to extend by building out the relationships between your objects in the model section. After the model is set up you will now be able to add any additional calculations in the DAX (Data Analysis Expressions) formula language. There are two types expressions that you can create, measures and calculated columns. To create these, you can go to modeling, and select the option. When you do this, the formula bar will display. You can also right click on any column or field and select “New measure” or “New column” from those drop down lists.
New DAX Measure or Column
Other than the formula bar with intelli-sense, there are several built in tools that can help you build those calculations.
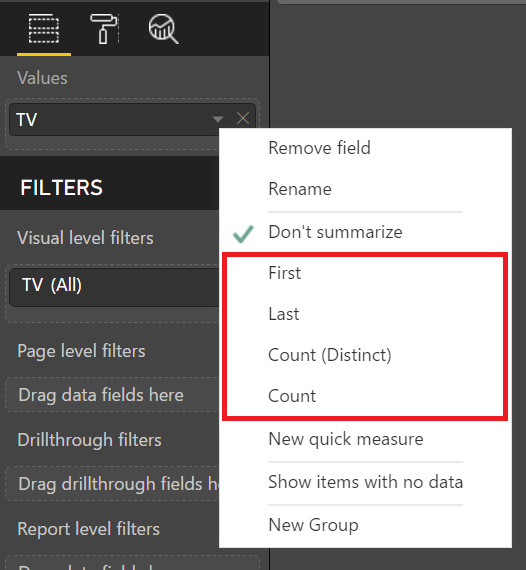
The first method is to Right Click on the desired field and select an implicit calculation from the drop down:
Using Implicit Calculations
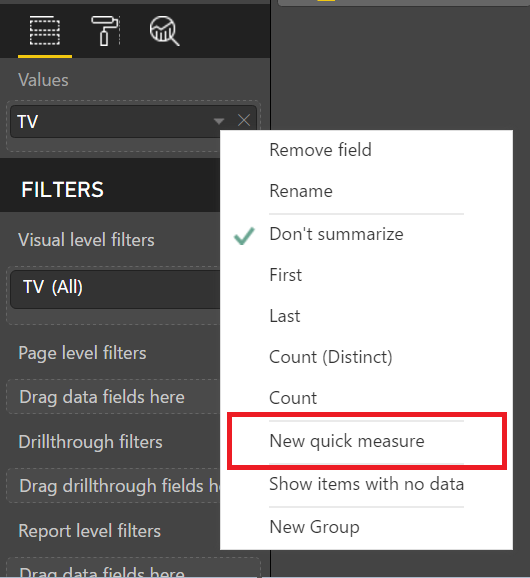
The second is Quick Measures. This can be accessed by using right click as described above.
Using Quick Measures
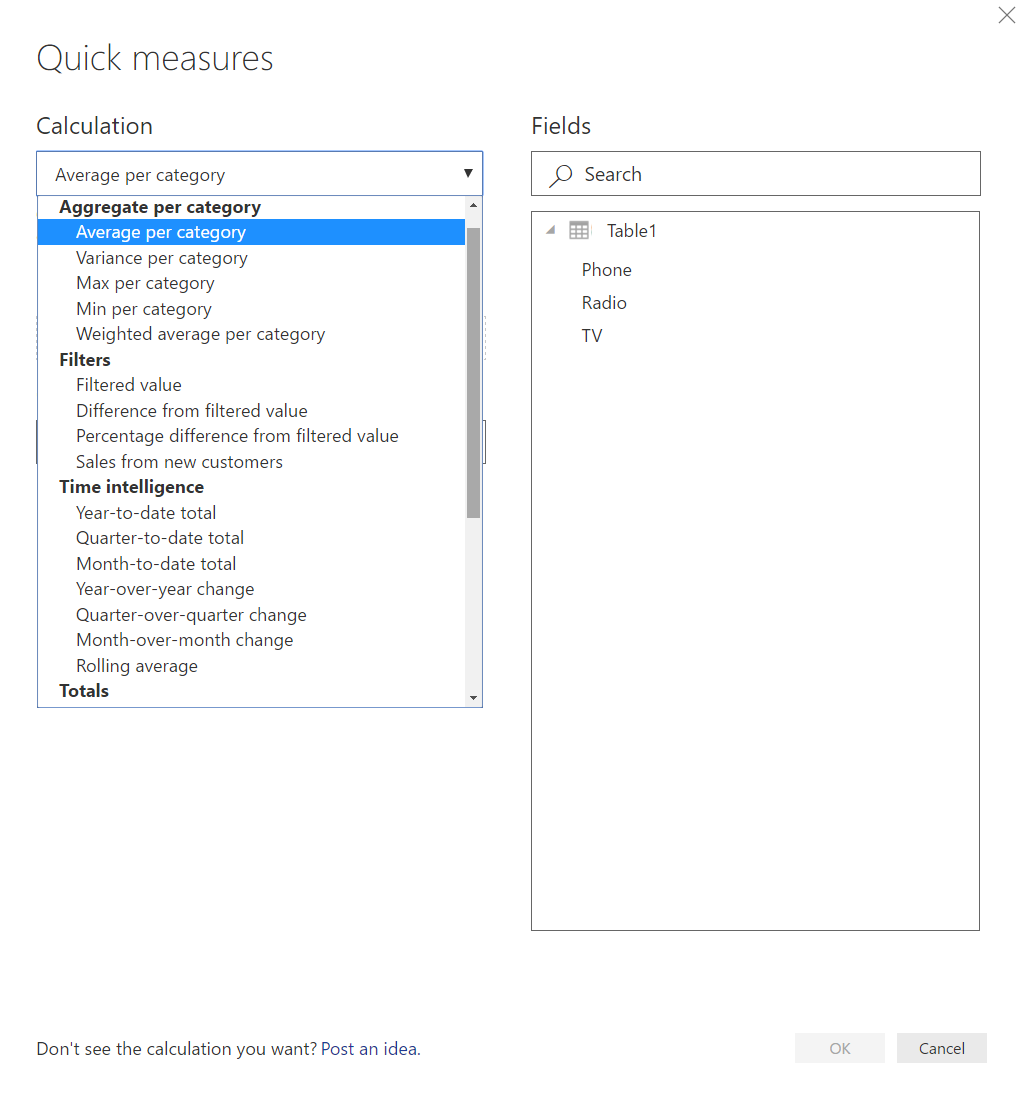
Here is an example of the Quick Measure dialog box:
Quick Measure Dialog Box
Quick Measures allows you to choose from a wide variety of calculations to generate a measure. Once the measure is created, you can interrogate the measure and see the code that was generated. Click on the measure (denoted by a little calculator next to the text) created by the Quick Measure dialog box to see the DAX code.
Here is an example of what that looks like:
Sample of Quick Measure
This is a great method to get your feet wet while you’re learning DAX.
Note: there are a lot of safety features added to these Quick Measures, such as, an “if” statement wrapped in a “isfiltered”. You might have to remove these bits of code in order to play with the measure.
When you have completed your report and publish the report & corresponding dataset to the Power BI Service, you will need to schedule a refresh. This will be required for any report which relies on the Import Connection. There are numerous use cases that surround whether or not you need a gateway, but a simple rule applies. If the data comes from an on-premises source, you will need one, for cloud sources you usually do not, but you can find in depth refresh documentation here.
The Import connection has the least amount of restrictions between the three methods, Import, Direct Query, and Live Connection. However, there are a few Import restrictions you should be aware of.
First, depending on your data source and the size of the data set, the processing of the model could take a bit of time.
Second, since all the data is being loaded into a table, there is a limitation on how big the file can get for successful publishing to the Power BI Service. That limit is 1 GB for free users & Power BI pro users, 2 GB for Report Server Reports and for Premium Users the size is only bound by the amount of memory you have purchased.
Note: The PBIX file can get as large as you want, however, it won’t let you publish.
Using Import is good when:
You can schedule your data to refresh
Data only needs to be refreshed periodically
Can be refreshed up to 8 scheduled refreshes in a day (restriction from Power BI Service)
The amount of data your importing is relatively small (doesn’t need to scale)
You need to mash up multiple sources such as Azure SQL database and google analytics data sources
In summary, the Import method is the most flexible, provides all the tools to connect, mashup, extend and visualize your datasets within the Power BI Desktop. It is likely the most used connection type and is the default for all connections. The data you connect to is drawn in, and a copy created and used in both the Desktop and the Service. Scheduled refresh is a requirement for almost all scenarios, and it is likely a gateway is required as well if your data is not located in the cloud.
Get Data – Power BI Connection Types: An Introduction
Hi, I’m Seth, I am very excited to be a contributing on PowerBI.tips. Mike has done an incredible job curating fantastic content for the PowerBI Community. In this first blog I will introduce you to the different types of connections that you can make using the Power BI Desktop. We will identify the various types of connections. In future posts we will dive into specific examples of usage and tips in tricks.
When I say “Types”, I don’t mean connecting to databases, Excel, SharePoint, etc. Those are just different data sources. I’m referring how Power BI ingests or interacts with data sources that you want to connect to. Believe it or not, Power BI doesn’t always have to pull all your data into the Power BI Desktop file. Depending on what sources of data you are connecting to, you could not even realize that there are more options, or be uncertain of what they do. In fact, depending on what type of connection you choose you are also altering how the Power BI Desktop functionality works! Now that I have your attention, let’s jump into the good stuff.
First things first. The only time you will be faced with an option to choose a type of connection, are when you connect to a data source that support multiple connection types. If all you connect to is Excel, you would never see an option in the dialogues because it only supports one type of connection.
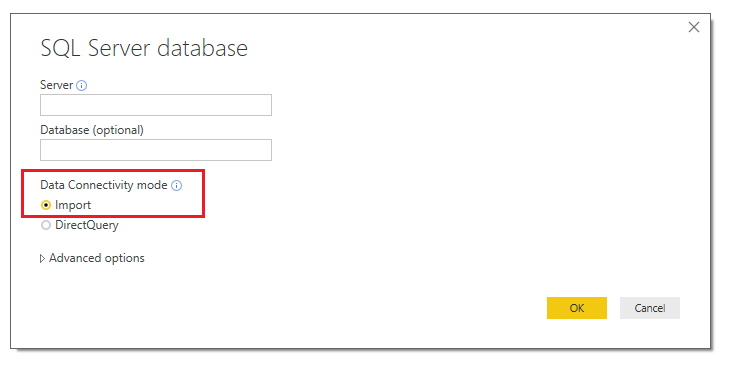
There are really 3 main types of connections. The first is the most widely used, and is the default when connecting to most data sources. It is Import. This connection will ingest or pull the data from the data source and become part of the PBI Desktop file. An example of where you would select import Is in the SQL Server dialog box.
SQL Server Import
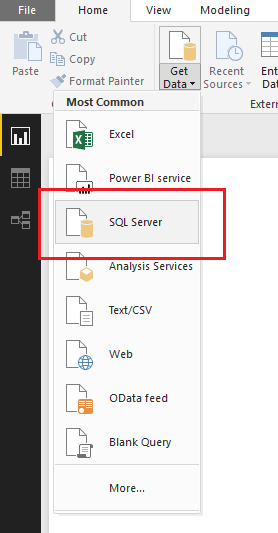
You can import data from a SQL Server by clicking Get Data on the Home ribbon.
Get Date SQL Server
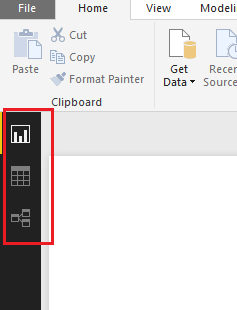
The import connection type allows you to use the full capabilities of the Power BI Desktop and you can manipulate it however you see fit. A way to validate this is by looking at the left-hand navigation and you will see three selections. The top selection which resembles a bar chart is the Report Page. This is where you would place all your visuals and develop your report pages. The second item from the top, which looks like a table is just that, the Data view in a table form. This lets you see all the data contained with a loaded data table. Finally, at the very bottom, the relationships selection. This is where you will see multiple tables and the connections between the tables. The relationships section feels like working SQL or in Microsoft Access.
Import Options
The 2nd connection type is Direct Query. Notice in direct query mode the third item, relationships has been removed. The direct query connection type is only available when you connect to certain data sources. The list of the data sources that are accessed using direct query can be found here. This connection is unique in that the data does not get loaded into the PBI Desktop. What happens, is that Power BI can communicate in the language of the data source and request information as you interact with your Power BI Visuals. The useful thing about this connection is that the data never leaves the data sources, it is only queried. Direct Query does limit what you can do from a data manipulation perspective. Power BI assumes you are already doing all the necessary data manipulations in your source. As a result, you don’t even have the option to mashup data and that selection is removed in the left-hand nav.
Direct Query Options
The 3rd type is Live Connection. There are only 3 data sources that support the live connection method at this time. All of them are a type of (SSAS) SQL Server Analysis Services. Those types are Multidimensional, Azure Tabular and Tabular on premises. The live connection type is the most unique in that it recognizes the full model or cube that you’ve created. Power BI Desktop turns off all data prep features. Thus, the user is given a bare minimum in formatting and report side calculations. All the heavy lifting is done on the server that supports the model and Power BI is only used as a reporting tool. This connection is used mainly by IT and enterprise implementations. If one looks at the left-hand navigation, you quickly realize that it is the most restrictive in terms of what can be done in the Desktop itself.
There is a fourth Live Connection that defaults to the connection type, and this occurs when you use the Power BI Service as a data source. This connection is using a SSAS connection, only the end users don’t need to set anything up other than having dataset to connect to in the Service.
Live Connection Options
Finally, there are two types of connections that dive a bit deeper than what comes with the Desktop out of the box. Those are Custom Data Connectors and API/Streaming. For the time being, we’ll leave these as just high-level points for now, and dive deeper into them in the specific articles in the future.
I hope you’ve found this initial primer useful. As this series continues we’ll dive into some of the reasons for using each of these types of connections, why you would want to, and the positives and negatives in choosing which one, provided you have a choice.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.