Tommy and Mike had a blast discussing the state of Data Science as it relates to Fabric. Microsoft is pushing into Data Engineering and Data Science by adding easy to use experiences. Learn from MVPs where you should invest your time with Fabric as it relates to Data Science.
This 4-episode series explores how data scientists can adapt to new technologies like Microsoft Fabric, the relevance of Power BI in data science, and whether traditional BI tools are being replaced. Each episode is about an hour long and offers deep insights for professionals navigating the modern data landscape.
Power BI continues to grow and strengthen its position in the enterprise space. A feature that you may not be aware of, but can be extremely valuable, is the ability to certify datasets. This capability offers organizations a way to help end users identify that certain datasets are more concrete than others. In this episode we discuss different criteria by which we think a dataset should reach a promoted or certified level. Do you use this feature? Do you know the difference between a Certified vs. Promoted Dataset?
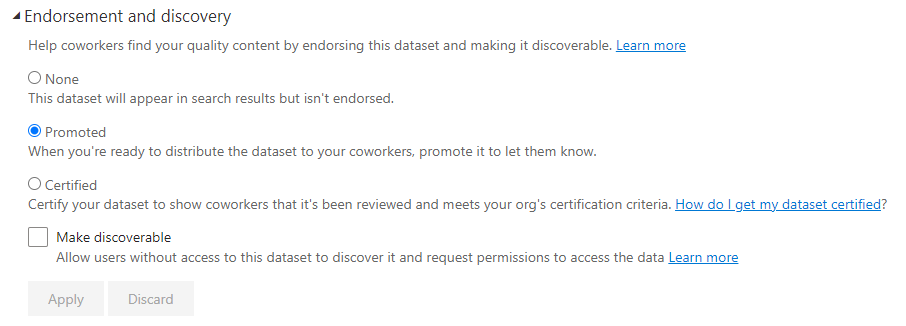
Promoted Datasets
Sample of Promoted Dataset Setting
This endorsement doesn’t have any guard rails. Any user with edit permissions on a workspace can add a promoted dataset/report. Business users should have a clear idea of what a promoted dataset means. However, this certification setting does not have any gates for sign off from admins or user bodies. The end user should have confidence in the accuracy of data, but there is no direct governance that requires it.
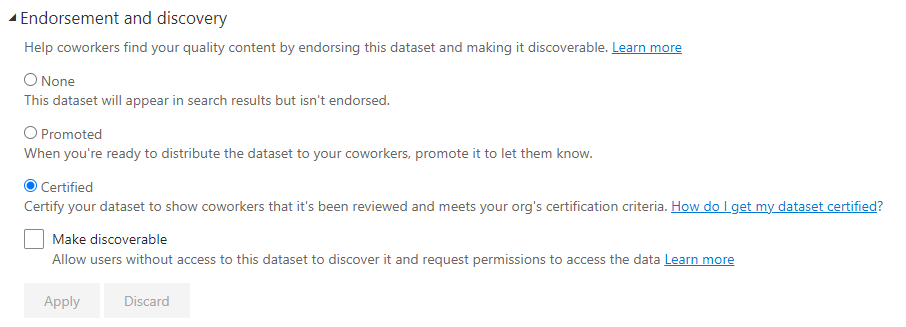
Certified Datasets
Sample of Certified Dataset Setting
We spend a lot of time discussing and getting some great feedback in the live chat around this area. The Certified endorsement can be tightly controlled. It is a setting that is allowed for admins or a governing user to implement. This endorsement can carry a significant amount more weight. It should imply that there are a series of steps, processes, and reviews that ensure the data is as trusted as possible. Join us as we explore what should or shouldn’t be a requirement using these endorsements. The best ways to implement these features and the value they provide to your overall implementation.
If you like the content from PowerBI.Tips, please follow us on all the social outlets to stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel, and follow us on Twitter where we will post all the announcements for new tutorials and content. Alternatively, you can catch us on LinkedIn (Seth) LinkedIn (Mike) where we will post all the announcements for new tutorials and content.
As always, you’ll find the coolest PowerBI.tips SWAG in our store. Check out all the fun PowerBI.tips clothing and products:
The Business Ops tool is designed to simplify your Development Experience with Power BI Desktop. There are a lot of challenges remembering where all the best power bi external tools are stored. Many MVPs contribute amazing projects to make your development experience better. The installer is intended to streamline and increase your efficiency when working in Power BI. Download this installer and you can add all the best External Tools directly into Power BI Desktop. Our release includes all the best External tools for Power BI Desktop. This will enable you to have a one stop shop for all the latest versions of External Tools.
If you like the content from PowerBI.Tips, please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn, where we post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store! Check out all the fun PowerBI.tips clothing and products:
To say this another way. Not all columns have datatypes in DAX, specifically speaking to using dynamic ranking with an “Other” category. Let me explain.
The Tabular model is comprised of tables with typed columns. This is a truth learned in one’s Tabular infancy. Whether the table is imported, calculated, or Directly Queried does not matter; all tables have columns with explicitly defined types.
DAX is the language of the Tabular model. It has less type discipline than tables in the Tabular model. Measures can have a Variant data type. Implicit type conversions abound. Nor are DAX expressions limited to returning scalar values. DAX is a query language. An expression may return a table. When defining a table in DAX, projected columns have no explicit type. Each row’s value is calculated independently and its type depends on its value. This is the phenomenon we seek to explore in this post. If this seems unsurprising, you can probably stop here.
A practical scenario
Here is the scenario where I discovered this. I was helping a colleague with a dynamic ranking measure and aggregation. The requirement read:
Show the top for production plants as ranks 1 through 4. Group all others ranked 5 or lower together as “Other”.
We have three tables:
a fact table 'Fact'
a dimension table 'Dim', related to 'Fact' with the relationship 'Fact'[DimKey] <-N:1- 'Dim'[DimKey]
a disconnected table, 'Rank Selector', with the values: “1”, “2”, “3”, “4”, and “Other”.
We started with a measure [Agg] as our base measure.
Agg = SUM ( 'Fact'[Value] )
[_Rank (variant)] is a helper ranking measure, returning a rank 1-4 or “Other”.
_Rank (variant) =
VAR rawRank = RANKX ( ALL ( 'Dim' ), [Agg],, DESC )
// note this value is either a number 1-4 OR the string, "Other"
VAR groupedRank = IF ( rawRank <= 4, rawRank, "Other" )
RETURN
groupedRank
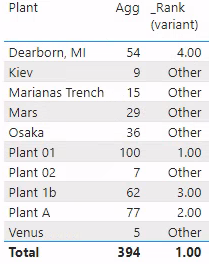
Below is a screengrab of these two measures evaluated against our 'Dim'[Plant]. As you can see, [Agg] returns a value for each plant. The top four plants have ranks of 1, 2, 3, and 4. The other plants all have the same rank, “Other”. This is all as expected.
'Dim'[Plant] with [Agg] and [_Rank (variant)] measures, working largely as expected. Each dim value has a value for [Agg] and a rank of 1-4 or the string, “Other”.
The issue reared its head when we attempted to use these ranks to define a new visual based on 'Rank Selector'[Rank]. We defined a measure to show [Agg] based on the plant’s rank (1-4 or “Other”), rather than the plant name. Note that 'Rank Selector'[Rank] is a column in a data model table, with Data type: Text. Our expectation is that we will see a table like the image below.
A table visualization showing six rows with labels: “1”, “2”, “3”, “4”, “Other”, and “Total”; and showing an aggregate alongside each.
Wherein our heroes encounter a challenge
[Ranked Agg (variant)] is the display measure to show aggregations against 'Rank Selector'[Rank]. We wrote the variant version you see below first, not realizing the perils that laid ahead. (Correct implementations follow later.)
Ranked Agg (variant) =
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (variant)],
"@val", [Agg]
)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
VAR result = SUMX ( currentRank, [@val] )
RETURN
result
When we visualize this measure against 'Rank Selector'[Rank], we get the result below.
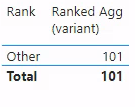
A table visualization showing only the 'Rank Selector'[Rank] value “Other” and “Total”. Specifically, we do not see any value for ranks “1”, “2”, “3”, or “4”.
A table visualization showing only the 'Rank Selector'[Rank] value “Other” and “Total”. Specifically, we do not see any value for ranks “1”, “2”, “3”, or “4”.
What is going on here? We see data only for the Rank Selector'[Rank] label “Other” but none of the numbers. Let us walk through the measure step-by-step to understand this result.
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
rankContext captures whatever the current filter context is for 'Rank Selector'[Rank]. This is one or a collection of the values: “1”, “2”, “3”, “4”, and “Other”. For a detail row of a table visualization, the context contains exactly one of those values. For a total row (assuming no other slicers or filters), the context contains all of those values.
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (variant)],
"@val", [Agg]
)
ranked is a table with all rows and columns of the data model table 'Dim' and two projected columns, [@rank] and [@val]. For any row, i.e., for any specific plant, [@rank] is one of 1-4 or “Other”. Many rows may have [@rank] = "Other". We do not expect ties, so there are exactly four rows with numeric ranks, one each for the ranks 1-4. (This table looks like the first table visualization screenshot above.)
The critical part of both the ranking logic and the phenomenon we are exploring is in currentRank. This is a subset of the table, ranked, holding only the row or rows which have a [@rank] value that exists in the filter context captured in rankContext (again, one or a collection of the values “1”, “2”, “3”, “4”, and “Other”).
Note, that we see data only for the Rank Selector'[Rank] label “Other”. As you recall, our [_Rank (variant)] seemed to work correctly above – it definitely returned ranks 1-4, not just “Other”. 'Rank Selector'[Rank] has the correct values. We checked that our logic in [Ranked Agg (variant)] was correct. We verified in DAX Studio that ranked held the correct table. We even got to the point that we checked whether VALUES was behaving as we expected in rankContext. (I will note that if you find yourself verifying the behavior of an expression as basic as VALUES ( 'Rank Selector'[Rank] ), then you, too, may find yourself questioning what has brought you to this point.)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
We continued checking and troubleshooting and identified that currentRank had binary state: either it would be an empty table or it would be a table holding only rows with [@rank] values of “Other”. It would never hold a row with a rank value of 1, 2, 3, or 4. It seemed that the predicate in our FILTER would never find 1 to be equal to 1, or 2 equal to 2, and so on.
How could basic logic be so broken just in this measure? There was much gnashing of teeth. Several head-shaped indents were beaten into the nearest wall.
DAX, the language, has a more permissive type system than the Tabular model
You may have observed some apparent inconsistency in my quoting or not-quoting the rank values above. In fact, I have been scrupulous to always quote values when referring to 'Rank Selector'[Rank], the model column with type Text, and to not-quote the rank values returned from [_Rank (variant)]. The column 'Rank Selector'[Rank] has exclusively string values. The measure [_Rank (variant)] sometimes returns a numerically typed value in the range 1-4 and sometimes returns the string “Other”.
In DAX, 1 = 1 is an equality test that returns TRUE. Similarly, 1 IN {1, 2, 3, 4} returns TRUE, because 1 = 1 and 1 exists in the table there. In DAX, 1 = "1" is an equality test that throws a type error. Numbers cannot be tested for equality with strings. They are different types. Therefore, a number can never be equal to a string. Thus, 1 IN {"1", "2", "3", "4", "Other"} also throws a type error.
The lightbulb moment
In [Ranked Agg (variant)], currentRank has a column [@rank] with type Variant. Sometimes, [@rank] has a value in the range 1-4, type Whole Number. Sometimes it has the value “Other”, type Text. When we evaluate the predicate [@rank] IN rankContext, there are exactly two possible results. Either we ask for an impossible membership test, “Is this numerically typed rank value in the set of Text values?”, or we ask whether the string “Other” is in that set. The first cannot succeed. The second only succeeds for the “Other” rank.
The Fix
The fix, then, is straightforward. We must always return a value of type Text in our ranking measure. Correct measures are below with comments highlighting the modifications.
_Rank (typed) =
VAR rawRank = RANKX ( ALL ( 'Dim' ), [Agg],, DESC )
VAR groupedRank =
// with an explicit typecast, our measure now *always* returns a string-typed value
IF (
rawRank <= 4,
FORMAT ( rawRank, "0" ), // force string type
"Other"
)
RETURN
groupedRank
Ranked Agg (typed) =
VAR rankContext = VALUES ( 'Rank Selector'[Rank] )
VAR ranked =
ADDCOLUMNS (
ALL ( 'Dim' ),
"@rank", [_Rank (typed)], // the only difference here is using our typed rank helper measure
"@val", [Agg]
)
VAR currentRank = FILTER ( ranked, [@rank] IN rankContext )
VAR result = SUMX ( currentRank, [@val] )
RETURN
result
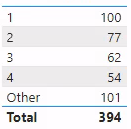
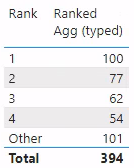
The measures above give us the results we expected all along, as you can see in the table visualization below.
A table visualization showing 6 rows with labels: “1”, “2”, “3”, “4”, “Other”, and “Total”; and showing the correct values of [Ranked Agg (typed)] alongside.
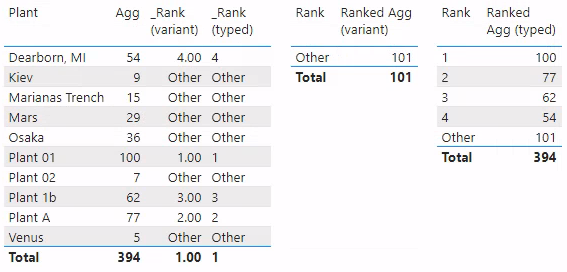
Below is a screengrab of all the measures in visualizations, so you can see the differences.
A screenshot with all three of the table visualizations shown prior in this post: the 'Dim'[Plant] table with [Agg], [_Rank (variant)], and [_Rank (typed)]; the incorrect behavior with [Ranked Agg (variant)]; and the correct behavior with [Ranked Agg (typed)].
Summary
Tabular model tables have columns of explicit type. DAX expressions have implicit types. Columns defined in DAX have Variant type. Each row has an implicit type based on its value. If such a column is a Calculated Column added to a data model table, then an explicit type must be assigned and all values in that column will be cast to that type at load time. When such a column is used as an intermediate step in some calculation, each row may have a different type. If your operations depend on types, you must account for this explicitly. This is especially relevant when operating on data model and DAX tables together.
Insights from the community
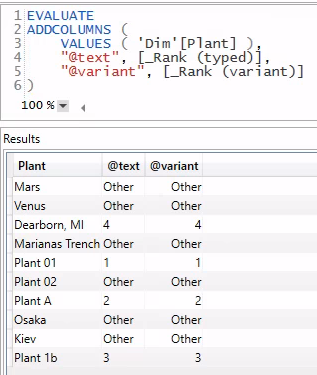
When talking about this with some peers, Maxim Zelensky (blog, Twitter) observed that there is no type indication in Power BI Desktop. Nevertheless, you can identify this sort of thing in DAX Studio. The result of a query such as that below will right-align Variant-typed values and left-align Text-typed values. This query references the included Power BI file and its results are shown in a screenshot below. You can observe similar alignment in the table visual shown above. In general, when visualized, numeric data is presented with right-alignment and textual data left-aligned. This practice predates Power BI; it is a general rule that Power BI and DAX Studio wisely adopted.
A screenshot showing the results of the above query, with [@text] left-aligned and [@variant] right-aligned.
Using the sample code and PBIX
Here is a link to download the PBIX that was used for examples above. This has four visuals to demonstrate the phenomenon discussed in this blog post. The first visual is a table with 'Dim'[Plant], [Agg], [_Rank (variant)], and [_Rank (typed)]. Of note in the first visual is left-vs-right alignment of the two [_Rank ...] measures. The second visual is a table with 'Rank Selector'[Rank] and [Ranked Agg (variant)], showing the incorrect results of the measure depending on a Variant-typed intermediate column, with a value only for rank “Other”. The third visual contrasts with the second, using [Ranked Agg (typed)] to show the correct behavior of the dynamic ranking and grouping logic, with a value for all ranks and a correct total. Lest one protest that the phenomenon above may be an artifact of using VARs, the last visual, on the bottom, shows an example that uses no VARs and references no other measures. The behavior of this last visual is identical to the incorrect [Ranked Agg (variant)] version.
This past weekend, I was a man on a mission. There were two pressing reasons for a new release of Business Ops:
The authors of many popular External Tools released updates recently, so we needed to ship a new version of Business Ops with those updates included
Last week, Michael Kovalsky (ElegantBI.com) released a brand new External Tool called Report Analyzer (which we can already tell will be an instant classic), so we wanted to get it out there and into the hands of report developers ASAP
So, I toiled away most of the day on Sunday, cramming as much value as I could into the next version. And along the way, I learned some important new software development skills, including how to:
If you like the content from PowerBI.Tips, please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn, where we post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store! Check out all the fun PowerBI.tips clothing and products:
Replaces the source DataflowID & WorkspaceID on all Power Query partitions in the model
Similar to the previous script, this one is specialized for automatically replacing old DataflowID and WorkspaceID references in Power Query with new ones. Helpful in situations where you need to re-deploy an existing Dataflow and Dataset to a new workspace, and then re-link the new Dataset to the new Dataflow
Useful for quickly excluding specific tables from the model refresh, which you may need to do for any number of reasons, including troubleshooting, performance, etc.
This repo has lots of other useful Tabular Editor Scripts, and we add more every day, so check it out! Also, if you have some handy scripts of your own, you can Fork the repo and submit a Pull Request. Then, we will add your scripts to the collection.
Happy scripting, everyone!
James
If you like the content from PowerBI.Tips, please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn, where we post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store! Check out all the fun PowerBI.tips clothing and products:
This article describes Power BI Bookmarks tips, tricks, and best practices. Bookmarks are a powerful feature that can greatly improve the reader’s experience. However, there are several settings you should be aware of. Used incorrectly, they can become hard to maintain and often not display the intended functionality.
Power BI Bookmarks
This article will assume some basic knowledge on how to record or apply bookmarks. Please see this. If you are new to Bookmarks, you may want to watch this helpful video by Adam Saxton from Guy In A Cube.
It will run through an example of using a switch visuals bookmark group. If you have not seen this before, I suggest you watch this video, also by Guy In A Cube.
The rest of the article will focus on some tricks and tips using bookmarks, while walking through an example of a visual switch between a map and a graph.
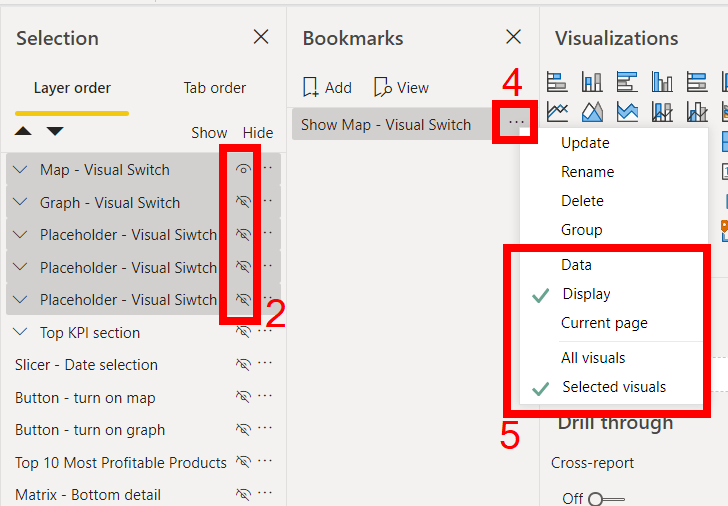
You should always update the bookmark settings when creating them. This should always be as specific as possible to the action they are trying to achieve.
Here is a quick breakdown of the settings:
Data: This captures items including filters and sort order. It does not capture if the item is visible or not.
Display: This captures whether an item is visible or not, without modifying filters or sort order.
Current Page: This will switch to the current page view if you apply the bookmark from a different page. If unselected, it will still apply the bookmark, but it will stay on the page you apply it from.
All Visuals: If this option is selected, it captures every setting on the page. This can include items in the filter pane, or even if the filter pane is open. I would recommend to never use this setting.
Selected Visuals: Selected visuals still only apply bookmarks to the visuals you had selected when you record the bookmark. You can select items by holding control and clicking on them in the selection pane.
In general, I try not to use both Data and Display together, as most cases bookmarks are just changing one of these fields. Previously, it was required to use bookmarks to navigate pages. However, this is no longer needed after new functionality allows this to be done with buttons directly. Therefore, I rarely use this feature.
One of the best Power BI Bookmarks tips – use selected visuals only. Recording bookmarks on all visuals often has unintended consequences and can be difficult to manage. Rarely is this needed and can become very hard when adding more visuals to the page.
Rename Your Visuals
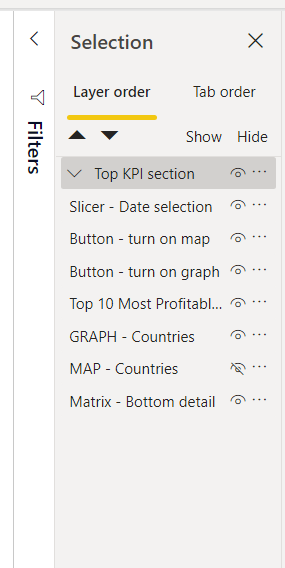
The first tip is to rename your visuals. Each visual is given a name, which can be viewed in the Selection Pane. By default, the name is usually the type of visual it is. This means if you have several slicers on a page, you might get a list of several visuals with the same name. While this is not an end user feature, it can make it difficult to identify the correct visual when developing.
We recommend renaming each visual when you add it. First, open the selection pane. Next, double click on the visual you have just added in the selection pane. Rename the visual to something that calls out what it is. Our recommended naming strategy is the following.
Visual - Description
Example of renamed visuals in a selection pane
Pro Tip: When a page contains multiple bookmarks it’s difficult to know what Bookmark touches which Visuals or Groups. Thus, when you are planning multiple bookmarks on a single page add an ID at the end of the Visual or Group. This will correspond to a number listed at the end of the Bookmark.
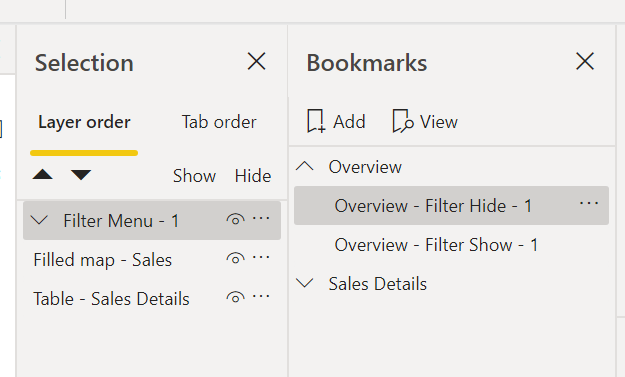
Record Power BI Bookmarks on Groups
Using groups has huge benefits for Power BI bookmarks. If you record bookmarks on groups instead of individual visuals. Now, any edits made on the content of the groups will flow through, without the need to re-record bookmarks.
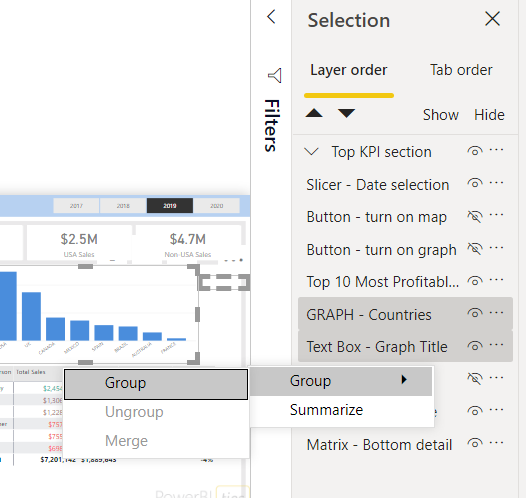
For example, let’s say I want a bookmark that switches a visual from a table to a map.
First, I’m going to make the groups. Open the selection pane. Whilst holding control, click on each visual that should be in the group. Right-Click on one of the selected visuals, then click the list option named Group then in the sub menu Group. You should also rename the group, so you know what it contains.
Note that to set up a group, you need at least two visuals. In my example, I have a graph visual and a title. If you have just one, you can still set up a group. Simply add a blank text box or shape and group it with your visual. You can then delete the blank text box or shape and the group will persist.
HINT: Elements can be difficult to move or select after grouping. If you want to modify a visual, use the selection pane to select it easily. If you want to move it, click and drag the ellipsis to move it.
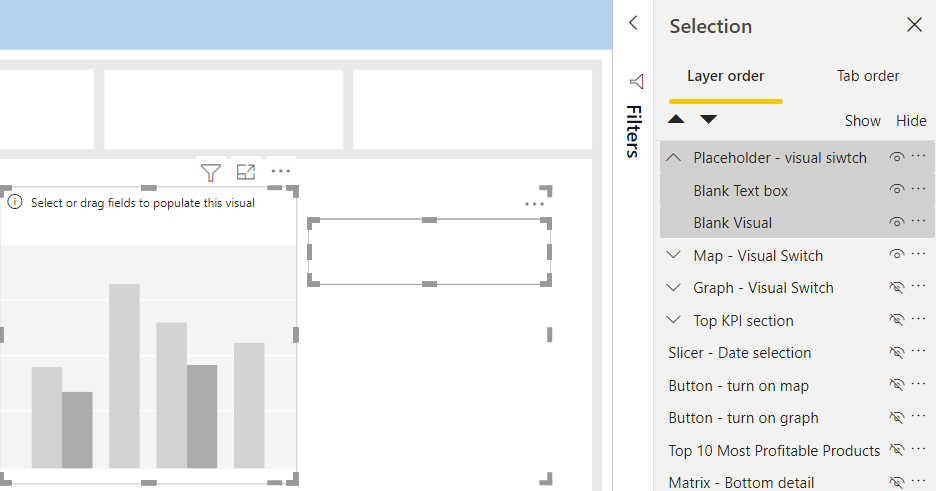
Add Placeholder Groups to Easily add More Visuals
Next, I will set up the remaining groups. Aside from the map group, I’m also going to add some placeholder groups. To do this, I will add a blank visual and a blank text box.
Next, I’m going to select the new group. Then I’m going to copy and paste using Control-C and Control-V to create three placeholders.
Now that all the groups are set up, it is time to record the bookmarks! For each group follow these steps:
Using control, select all visual groups including the placeholders.
Using the eye, hide all visual groups except the Map – Visual Switch.
Rename the bookmark in the bookmark pane by double clicking it.
Click the ellipsis to open the bookmark settings.
Deselect Data and Current Page. Change to Selected Visuals. The settings should look like the picture above.
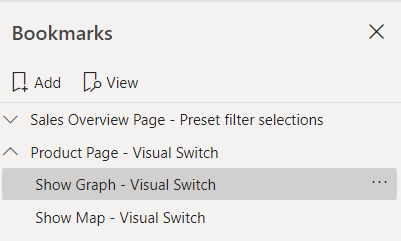
Rename and Group Bookmarks
Two more Power BI Bookmarks Tips are to rename the bookmarks and to group them. In addition to renaming your visuals when adding them, you should also rename your bookmarks. For the bookmarks themselves, I do action name – function. Secondly, you should group similar bookmarks together. For example, the bookmarks in the visual switch should be put in the same group. This group can also be renamed. I often like to include the page name in the group and then its function.
Example of Power BI bookmark groups and names
Pro Tip: You will want to provide a connection between the bookmarks and the visual elements on the page. By adding an ID at the end of the Visual or Group and the Bookmark you can create a traceable link. This is especially important when you have multiple repot developers working on the same report. Adding an ID signals to the next report developer that these bookmarks are influencing the associated items on the Selection pane.
Layers
For this section, you should be familiar with the selection pane. Remember that objects at the top of the selection pane are in front of those below it.
Now that we have our groups, it makes it simpler to have buttons. In my example, I will create a button that says Graph, plus a button that says Map. If we are switching visuals, it is useful to have highlighted what visual is presented. I will highlight with a blue background and bold text.
One way of doing this, is to layer text boxes behind the buttons. First, create the buttons at the that will contain the bookmark action. This button will be see-through and slightly larger than the text boxes.
Next, create the middle text boxes that formatted for the selected button name.
Finally, create the back text boxes that are formatted for the unselected button name.
Example of the button elements
Keep it Tidy
Once we have repeated for all buttons, we can tidy it up. First, place all button elements in the same position on the page. You can do this easily using the align function.
Then, place the middle text box inside the group it relates to. This means when the bookmark is applied, the selected format will be visible for the correct visual. The trick is that we will layer the elements, so this text box will appear in front of the unselected text box. The buttons will always be on top, so the functionality will always remain the same.
Group the front buttons together, and make sure they are in front of the text boxes. These control the functionality of the Power BI Bookmarks.
Group the back text boxes together, and make sure they are at the back.
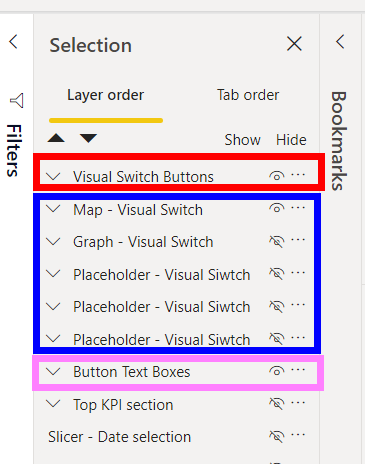
The layer sets: Visual Switch Buttons: These are the buttons that apply the bookmarks. This is the top layer and always visible. This contains the Front Buttons.
Visual Switch Groups: This is the groups we set up earlier. This contains the text box that shows the highlighted button name. As the text boxes are part of the groups, only the selected one is visible. The is the middle layer. This contains the middle text boxes.
Button Text Boxes: This contains the text boxes that go at the back and show the unselected value. This contains the Back Text Boxes.
Final Words
Out of all the Power BI Bookmarks tips, the one I would stress the most is: use the selected visuals setting. It will make your reports much easier to maintain!
If you are not convinced to use bookmark groups, it was recently announced at MBAS 2021 some extra functionality. This will allow users to apply whole bookmark groups to a page, automatically adding buttons when you add extra bookmarks.
I also described a similar tip using buttons almost two years ago. This uses slightly more advanced technique, and some functionality was not out then that is now. However, it is still valid and a viable option.
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
I was having a candid conversation with Phil Seamark from DAX.tips about Aggregation Tables. During that conversation, I was asking about patterns in using Aggregation tables. Within that 10 minute conversation I was blow away by all the possible patterns. Because of this, we pleaded for Phil to present these patterns to the Milwaukee Brew City User Group.
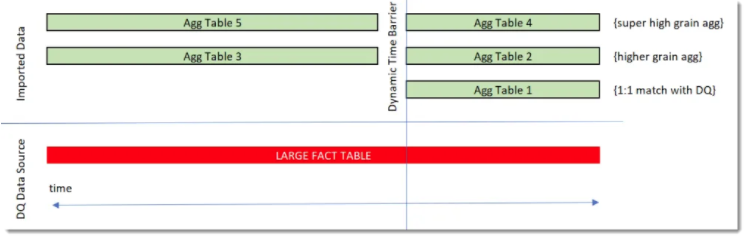
While these patterns are described in detail here are the various patterns that can be used for Aggregation tables. Also, Phil includes a great introduction, found here. For each of these articles Phil describes proper usage for the pattern.
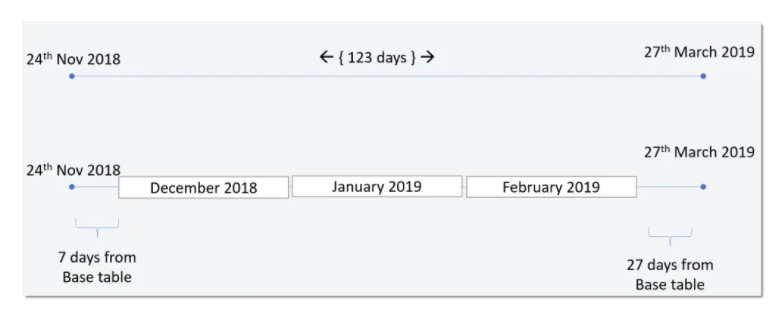
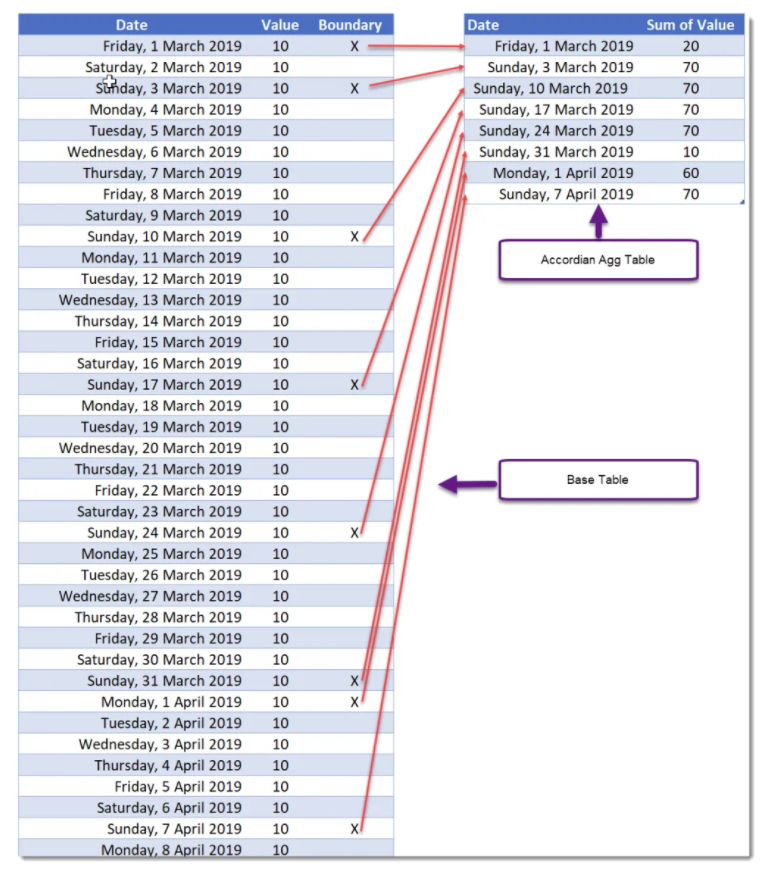
The Filtered Aggs would contain multiple Aggregation tables of the same data. But, each Agg table could contain different gains of data. For Example, data aggregated by Week, Month or Year.
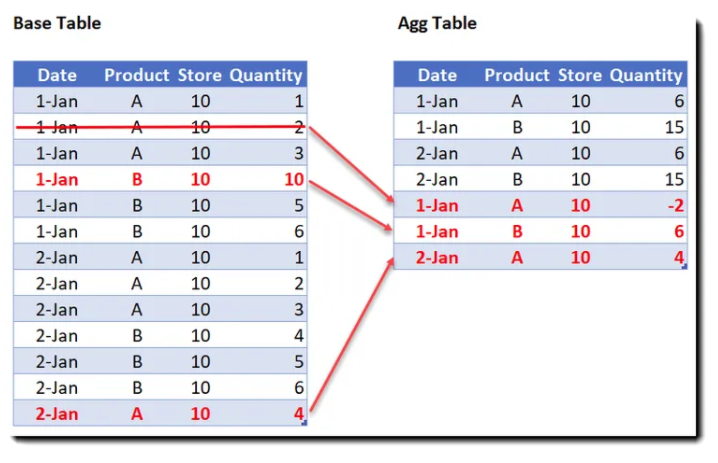
Finally, the Incremental Aggs. This type of aggregation would be used when aggregating transactions per day by store, and or product.
Thanks Phil
A special thanks to Phil for presenting. Since, we know you are a busy guy doing tons of great work. Thank you for taking time out of your day to present this wonderful topic. We hope you enjoy this exploration into Agg Tables.
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
Well Microsoft has done it again. They have added a great feature in the Power BI desktop release for December 2020. Direct Query to Power BI data sources is a thing. As a result, this means we unlock new Architectural patterns.
Enterprise Modeling
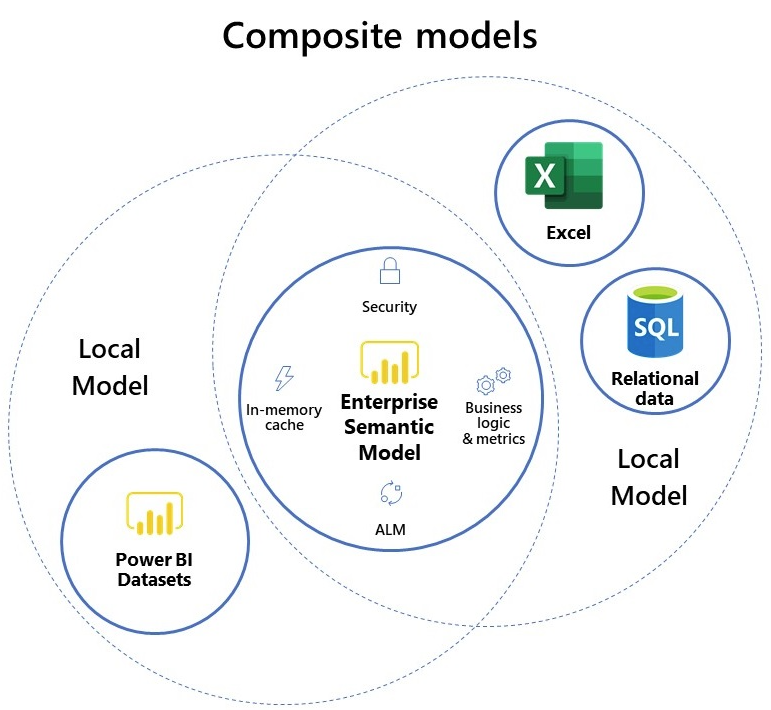
In the Microsoft Release notes we get a glimpse of our new normal. Previously, Power BI datasets could only direct query certain data sources. Here is a full list of data sources for Power BI Desktop. The Enterprise Sematic model is simply larger view of a data model.
Quick background on Composite Models. A Composite model is a data model. More specifically, a Power BI data model. Typically Power BI models have multiple data sources. Such as, Excel, or SQL server. For certain data sources we load data in one of two ways, Importing, or Direct Query. The Import method loads data into the Power BI file. While, Direct Query leaves the data inside the data source, but sends queries to retrieve data on demand. Learn more about Import and Direct Query in these articles.
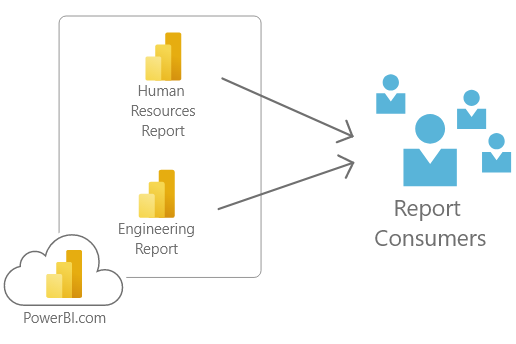
When we think of an organization there are likely hundreds of data models. These data models support by many different teams. Each model is solves some sort of problem. As an example, we can think about models developed for Human Resources. The Human Resource model informs the HR team about acquiring new talent, or track an interview process. Other teams such as Engineering track spend or project details.
Using this method, imagine a user who needs to see data from both human resources and engineering. Thus, a user would need to visit two different reports. Obviously value can given by combining multiple data models. This would enable the creation of a single report using data from both sources.
Direct Query for Power BI datasets
Now, lets consider the Enterprise Data model. In the Microsoft documentation this is called the Enterprise Semantic Model. We can think of the Enterprise Semantic Model as storing metadata linking tables of data and storing relationships between tables. Direct Query to PowerBI.com now lets us make models of models.
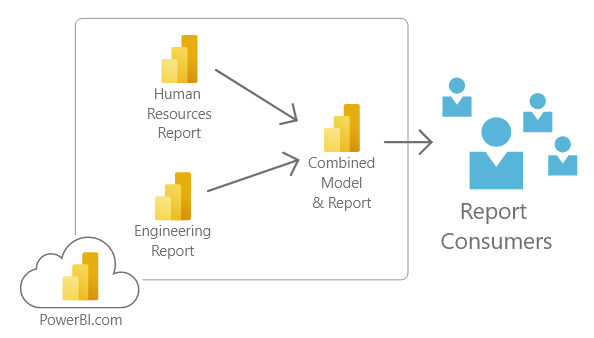
From our previous example now consider this architecture.
Report builders can now create a single model that queries other data models. This provides data from multiple subject matter areas. Thus, enabling a single report to combine data from multiple locations.
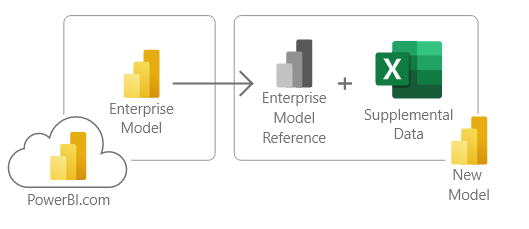
Centrally Managed Models
Often in larger organizations there will be different teams creating models. This means, you might not have access to modify an Enterprise build model. Again, Direct Query to models to the rescue. As a report author, I want to reuse an existing model. However, I would like to add more data to the model that would enrich my reporting. This may come in the form of a connected excel document. For this architecture consider the following diagram.
This new architecture is the ultimate success for self service business intelligence. Enterprise governed models can be enhanced by business users. Therefore, providing flexibility while controlling model governance and standards.
More Architecture thoughts
Power BI is evolving at a rapid pace. Because of this, Power BI is rapidly becoming one of the key tools. Therefore, more thought to Enterprise Architecture must be considered. Learn more about key architectural decision points in our previous articles, Data Architecture, and The Greater Data Solution.
Composite Models Conclusion
These are just some of my initial thoughts on this amazing new world we have. There will likely be many more designs and implementations from the community of Power BI developers. I’m extremely excited to see other patterns emerge from using Direct Query against Power BI datasets.
Read more from the official blog release and Microsoft documentation:
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
Check out the new Merch!
Hasta La Vista Data
Go Ahead Make My Data
PBIX Hat
Power BI Swag Now Available
Now you can get your favorite Power BI gear. Visit our PowerBI.tips clothing store to purchase your favorite items.
We just completed an amazing webinar from Parker Stevens over at https://bielite.com/ . In this webinar, Parker walks us through how to connect to the Power BI Admin APIs. The Admin API contains a wealth of knowledge for all activity within your Power BI tenant.
While there is a good amount of reporting built into the Power BI admin page, you may need more. This is why you would use the Admin APIs to gather all the activity data from within your Power BI. For more information, learn about the Power BI Admin Portal.
Parker takes us through a deep dive connecting to the Power BI admin apis and shows us how to build a robust dataset ready for Admins to produce the reporting they need.
Watch the Full Webinar
If you like the content from PowerBI.Tips please follow us on all the social outlets. Stay up to date on all the latest features and free tutorials. Subscribe to our YouTube Channel. Or follow us on the social channels, Twitter and LinkedIn where we will post all the announcements for new tutorials and content.
Introducing our PowerBI.tips SWAG store. Check out all the fun PowerBI.tips clothing and products:
Check out the new Merch!
Hasta La Vista Data
Go Ahead Make My Data
PBIX Hat
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.