Let’s Talk Default Semantic Model – Ep. 362
In this episode of the Explicit Measures Podcast, the team digs into Let’s Talk Default Semantic Model—what it is, why it matters, and how to think about it in real-world Power BI projects.
News & Announcements
- Fabric Community Conference Europe Recap | Microsoft Fabric Blog | Microsoft Fabric — We had an incredible time in our host city of Stockholm for FabCon Europe! 3,300 attendees joined us from our international community, and it was wonderful to meet so many of you in person. Throughout the week of…
- Update to Direct Lake documentation | Microsoft Power BI Blog | Microsoft Power BI — We recently made a significant update to the Direct Lake documentation. Direct Lake accelerates time to data-driven decisions by unlocking incredible performance directly against OneLake, without the need to manage…
- Differences between Dataflow Gen1 and Dataflow Gen2 - Microsoft Fabric | Microsoft Learn — Compare differences between Dataflow Gen1 and Gen2 in Data Factory for Microsoft Fabric.
- PowerBI.tips Podcast — Subscribe and listen to the Explicit Measures podcast episodes and related content.
- Power BI Theme Generator — Power BI.tips - The worlds best theme generator for Power BI reports. Increase your speed to develop stunning reports using this free theme generator. Themes are essential for any report developer’s tool belt. Visit…
Main Discussion
Fabric’s Lakehouse (and Warehouse) can auto-create a default semantic model, which sounds convenient—but it has real implications for governance, ownership, and how your org builds “one source of truth.” The crew talks through when the default model is helpful, when it’s dangerous, and how to keep it from turning into semantic sprawl.
Key points:
- Default models are great for quick exploration and accelerating time-to-first-report, especially for smaller teams.
- In larger orgs, you still need intentional semantic modeling: curated measures, naming standards, and a clear owner.
- Be explicit about security and sharing—auto-generated artifacts can accidentally widen access or create confusion about what’s “official.”
- Decide whether you want one shared model, multiple purpose-built models, or a layered approach (explore vs. curated).
- The platform can generate a model, but it can’t generate agreement on definitions—your team still has to do that work.
Looking Forward
As the platform evolves, keeping an eye on how semantic models are created by default (and how users discover them) will help teams avoid accidental sprawl and improve consistency.
Episode Transcript
0:35 good morning and welcome back to the explicit meters podcast with Tommy Seth and and Mike good morning everyone it is morning it’s I guess it’s a good one how are you how are you wow you’re starting up with anistic day today yeah it’s been a hard week for you oh nailed it nailed it says a lot well it’s another day I haven’t died yet yeah more along the lines of it is it th is it Thursday is it okay it’s Thursday yep it’s thday I I get this very often it feels
1:06 thday I I get this very often it feels like I get to Thursday I’m like man it doesn’t I I can’t tell if it’s been a long week or I’ve just been enjoying or just been a lot of work it’s just very busy all the way up until Thursday I get to Thursday I’m like man we’re almost to a weekend great so awesome indeed jumping on in Let’s our main topic for today is talking let’s let’s talk default semantic model so that is our our main topic for today we’re going to talk about the what happens when you create a Lakehouse that Lakehouse creates the default centic
1:36 Lakehouse creates the default centic model we’re going to unpack this as people who’ve been doing or MVPs who’ve been playing around with the semantic model and now fabric here for a number of months and our opinion where where’s the advantages of it are there some weaknesses to it what are your considerations when you want to use or build reports off of that default semantic model before we jump into our main topic Tommy you have a news article for us here so we had an official fabric log post again I don’t know how many people in our world is going to pertain to but by yourself doing what they do so the
2:07 by yourself doing what they do so the title of the article is enhancing open source Fabrics contribution to Flamel I guess that’s you say it and scalable autom ml so basically they have some open source libraries around some Apache spark workloads I think a lot of the I don’t think it’s all the backload that they’re doing with fabric now and fabric spark but they continue to open up a ton an open source and how people can collaborate with it and build off of it
2:38 collaborate with it and build off of it this is where I think a lot of this is going to go right so now that we have well a scalable autom ml which is interesting I think if you talk to like actual data scientists automatic ml anything around that space is just very they’re very Ley about it the Flamel I guess is how you say fast and lightweight autom ml autom ml is an open source library to streamline the process of automating learning tasks autom ml is one of their ke key
3:08 autom ml is one of their ke key capabilities this is it’s interesting I’ll have to get dig in a little bit deeper and see what I need to to learn more about this topic my topic my fundamental challenge with this is in order to do this you need a lot of data in your Lake from a bunch of sources we’re still struggling to get a lot of that done we’re we’re still trying to figure out how to get everything into the lake first so I think this is a great opportunity but I’m not sure if a lot of organizations are going to be ready to jump in with both feet and start doing AI generated
3:39 both feet and start doing AI generated things it will be a wave that comes on top of now that we have all the data in the lake we’ virtualized it we’ve got shortcuts whatever I think there’s going to be a lot more investigation or people need to will need to spend time learning this but right now I feel like a lot of companies are still just trying to figure out what is what is fabric how do we use notebooks how do we get the data to the lake as quickly as we can you to the lake as quickly as we can it’s almost like cheating when you know it’s almost like cheating when you bring all these groups together because the the data science and ML and all all the stuff after the fact they’re looking good they’re looking good right now already releasing features that
4:10 now already releasing features that you’re not even ready to use yet that’s right I think that’s their MO though if it’s not downloading it yep that’s right it’s interesting I’m looking forward this one so this will be interesting to see where they go with this I think there’s been a big push for Microsoft just to start doing ml projects on top of fabric I feel like there was a a worldwide like hackathon AI hackathon that was trying to happen
4:41 AI hackathon that was trying to happen as well as well so I’m very hopeful for this space because I think the fact that we now have python we have spark we have things that are a bit more open source and we can bring those tools to us inside fabric I think we’re going to see a lot of very good blogs acceleration I I think we’re going to see in the same way we’ve seen a lot of like large language models there’s every single day another software app hey use cursor use another version of chat GPT open AI is pushing out another model I think we’re going to see another wave of all these Innovative AI based solutions to solve
5:13 Innovative AI based solutions to solve problems so I I’m just it’s coming I think I I think we’re going to get to a point where it’s going to be very a flood of new tools that we’re GNA get in our in our hands it’s funny when you think about because obviously we’re so focused on just the fabric playground and the AI in there but Microsoft’s doing a ton in obviously the data space but really in AI too one of their biggest open source models is called fi and they’ve been working with like a of agents and all this is
5:43 with like a of agents and all this is really only open source interesting that doesn’t touch fabric at all I feel like a lot of this AI stuff starts with so even with the announcement of co-pilot cutting its cost in half right so you’re you’re using co-pilot and you saw a number of compute unit usage items that we getting pushed back to this the admin capacity app even already I’m seeing Microsoft the wave the first wave of AI is just get it working it’s expensive it’s not super cheap and I think we’re
6:13 it’s not super cheap and I think we’re starting to see areas of AI that are getting optimized now it’s now becoming less less costly to run it’s becoming more user user friendly there’s there’s a lot more useful parts coming to it even with the co-pilot inside Dax query View it was interesting at the beginning it did a couple things one or two things but it’s getting pretty powerful now and it’s doing a lot better I think in Dax quare riew they’re they’re definitely tuning these models and they’re becoming more and more useful as I’m using them
6:44 more and more useful as I’m using them inside the application one thing I’ll just Clearly say the one that I love right now so again this is for Microsoft and for data bricks and my my two applications I love data brick has got an AI on it and you can ask it for help and debugging and other things like that it’s great and anytime I’m writing python in a notebook dude co-pilot excels there it is so good when you’re writing code things so I’m really excited to see I haven’t played with I gotta be honest here I haven’t played with co-pilot or anything around AI in SQL
7:16 co-pilot or anything around AI in SQL notebooks or using a SQL data warehouse but I feel like that would be another really good useful thing because there’s a lot of little things in SQL like oh I don’t know how to do this or I wanted to do a do a rollup not many people know how to write a rollup so why can’t the SQL just tell you how to do here’s the P it’s a pattern it’s a so SQL is very pattern-based it should be able to help me write that code a little bit better anyways I’d like to see it do that I I I share the same I we’re we’re talking about data bricks but that I’m no lie if
7:48 about data bricks but that I’m no lie if if we we’ve talked about Ai and how code generation would probably be the the place to speed things up it it’s good it just seems to get better too like longer you spend in a query or you’re revising things or adding things to it I’m I’m really surprised actually like how much code it it be like it starts to generate like I’ll do case statements now where all of a sudden just like oh you must want to do and it’s like rest the case
8:19 want to do and it’s like rest the case statement it’s like yeah yes that’s exactly what I wanted to do actually like enter right like yes and I think that’s where there’s a ton of opportunity where Ai and co-pilots and whatever the things are going to show the most benefit right out of the tooling and I it’s available in in other tool sets as well but sure we’re heavy data bricks users and their their solution is I’m enjoying it get a lot of use out of it every day okay there’s a lot of there’s there’s also
8:49 there’s a lot of there’s there’s also one other thing that it does too yeah which is which is error checking right like when you’re when you’re it’s not just like the prompt to finish the code it’s you have an error you must want to do this and it it highlights what what is wrong and then gives you the answer and like Escape if you don’t want it enter if you do and just like yeah fix it yes so very very useful tool now that you bring this up and
9:21 tool now that you bring this up and now that you’re talking about this stuff I just gotta I gota bring one more com comment this is this is random on the off the cuff I was reading some articles articles yesterday I think I think we have a new player in town okay I’m gonna I’m going to go on a thing here is this a hot take this is probably a hot take actually I saw an announcement a blog post that
9:42 I saw an announcement a blog post that came across data bricks and said introducing data bricks apps Seth we’ve we’ve talked about this before Microsoft has pretty much taken the market from the other visualizations tool like it’s it’s it’s by far the best visualization tool it is by far the cheap to start getting start using it it integrates with the tabular engine model it’s super fast all these great things right it’s doing incredible stuff I saw datab bricks put out this thing called datab bricks apps and it
10:12 thing called datab bricks apps and it talks about using AI in your app it talks about custom data visualization it talks about selfs serve analytics and it talks about data quality monitoring many of this feels like datab bricks has taken the approach of and and let me give give you context here datab bricks is the company that has made the Spark engine it is it is what is built most of the infrastructure that we use and and move around data today so they are the they are the initiators the creators in this there is some really I
10:44 creators in this there is some really I would say competitive features that are coming into this datab bricks app thing that potentially would challenge us or is is I think stepping on some of the toes of where powerbi is going or where powerbi is on on top of the the data warehousing and the section of doing the data engineering for powerbi so I don’t know where this is going to go but I know Seth you and I talked a little while ago said imagine what if data bricks actually did step into the table and said look we’re great at the data stuff we’ve got the engine we know
11:15 data stuff we’ve got the engine we know what we’re doing the backend side of things are taken care of let’s start playing in the visual side let’s give people an incredible experience to build reports and dashboard and really go all in with serverless data bricks go all in with building the visual out output of the data and I thought man that could be a huge challenge to Microsoft and as I was thinking about it one I was like whoa this is a cool feature the second thing was whoa
11:45 feature the second thing was whoa Microsoft better take note of this and they better not be dragging their feet or dragging their Knuckles on any of the visualization side of things because I there’s another company coming to play ball at this visualization layer this could be interesting anyway have to yeah I’m going to have to dive more into that because if if we as we were talking about I forget what topic it was recent in one of the other previous episodes like all of like one of the data mesh Concepts right the the distribution and engagement with end
12:16 distribution and engagement with end users and fabric has that right it’s always had powerbi but it’s in the back end and data bricks hasn’t data bricks is the big engineering tool and yes and just briefly through this like if apps are designed to be the interface for more of your end users consumers yeah yeah like it’s already a a multi-dimensional type of environment where you can have different domain centers and things like that so that
12:46 centers and things like that so that that’s very interesting so I’ll have to see where this goes this will be interesting to see what datab Bri produces here but I what I one thing I don’t see data bricks doing and this doesn’t mean it can’t happen but there’s this whole concept of like the tab your model the caching the data into memory and using that data to very quickly rip across the report and stuff I don’t see them doing that yet it may be coming I don’t know it it seems to me like data brick says well we know the best way to access these data and Delta tables we can self-optimize a lot of things for you
13:16 self-optimize a lot of things for you they’ handle a lot of the the leg work for you but until they actually get the semantic model they’re going to have a hard time competing against Microsoft in the in the tabular engine space because Microsoft has done so much work to keep that front content extremely fast and and again I think users really have I think the market has moved from I used to build Excel files that they still do that to be clear we’re not saying we’re not doing Excel anymore I think the market has moved from I want to put visuals on the page and I expect to
13:47 visuals on the page and I expect to click things on visuals and have everything changed across the whole page that is a thing that people I think are now used to and after doing RBI for like what eight nine years how long it’s been out now out now it’s an expectation if you don’t have a data visualization tool that has multiple visuals where you can click and select and adjust things in a in a window page and everything adjusts I think people weren’t going to use it because they’re just so used to that powerbi experience or they they expect it now oh man you’re derailing me there goes my day I got to look more into
14:18 goes my day I got to look more into this just just just making a note that said this was announced I don’t it’s probably going to get better but like this this to me put a couple mind notes in my mind I thought this is interesting there could really be some Challengers to the market here and I it’s good to have to be a large company and not have any competition with people paying from your visual space is not a good thing having no competitors that are that are playing in your field means no innovation for us as us consumers I want a little bit of
14:48 consumers I want a little bit of competition right I still want powerbi to be the best thing out there because I love it and i’ I’ve basically seted my career around doing it so I’m still going to push and still learn about it but there’s other tools now that I think are are catching on and saying hey we could probably do some of this or carve out some some market for us that are that we already have customers are doing data things so I I see see this is being we should pay attention to this we should watch for it sorry that was a very big hot take I I’m looking forward to seeing where they’re going but right off the same thing where we’re talking
15:19 off the same thing where we’re talking about all these tools are doing more and more context for you the major player here Chad GPT actually came out with something that almost goes along with our conversation about co-pilot wanting to be more part of what we’re doing so now co-pilot’s a lot more like or a chat GPT is a lot more like vs codes co-pilot where there’s a new Mode called canvas mode for pro users and it’s really neat and it’s also all built
15:49 it’s really neat and it’s also all built within H chat TPT basically you submit as many articles coding pieces as you can that that pertain to it sure tell about the the conversation rather than writing in that line that it does it actually opens up new window and the like a thing called artifacts interesting yeah so that is gonna be a lot more in depth the one thing I hate about all these code tools as great as they are I don’t know if you’ve ever been working on something that’s a little long and you just say hey I am
16:20 little long and you just say hey I am looking for this this and this Ando done like I don’t know man you you give a little more working on something a little bit long I you need to give me a bit more context are youing a St the codee’s long okay but the time it takes the AI to fix it is quicker than you would think it would be because rather than going through everything I’m not sure if I use a so I’ll be honest I don’t use a ton of AI to help me fix code because most of what I write is 100% correct from the beginning but when
16:50 100% correct from the beginning but when I do use code I just usually use it to generate new code there are moments yeah there are moments if you correct the AI it will go no you’re right I didn’t take an count to this and then it’ll go through like oh I don’t want to be right that’s I right that’s this is this speaks to what Kurt’s mean this is this speaks to what Kurt’s article we talked about Kurt’s article about co-pilot and how things work I about co-pilot and how things work that is the challenge if you’re a mean that is the challenge if you’re a novice user you don’t know any better if you’re a more advanced user it it really supplements your power pretty well so
17:21 supplements your power pretty well so like I I think it’s definitely going to be a give and take thing here yeah it’s interesting that’s a good point Tommy I’m actually I don’t play I don’t have a subscription to chat GPT or guess open AI would be what it is I think you pay for one right you to have it one of the things that bug me right now is I would like to try even though we have notebooks we have Dax query view I’d really like to try different co-pilots against my code and there’s no
17:52 co-pilots against my code and there’s no way to do it you only get co-pilot it’s built into everything I wish I had the ability to like well let let’s let’s try cursor let’s try chat GPT let’s try these other large language models and I could replace them with what I wanted to use inside different notebook so for example if I’m paying 20 bucks for my developers to have GitHub co-pilot I want to use GitHub co-pilot in my notebooks inside fabric like that I want to bring that P that copilot with me I’m already paid for it I don’t necessarily want to use the
18:22 I don’t necessarily want to use the Microsoft co-pilot to do it excuse me anyways yeah maybe we should push on to our actual topic today we’re about 18 minutes in we still haven’t done the actual topic Tommy you want to give us some tea up the conversation here just which what are we going to talk about what should be our main topics here for that default model so yes we are diving into something that’s from the onset of Microsoft fabric has been part of it as a feature not a bug where anytime we
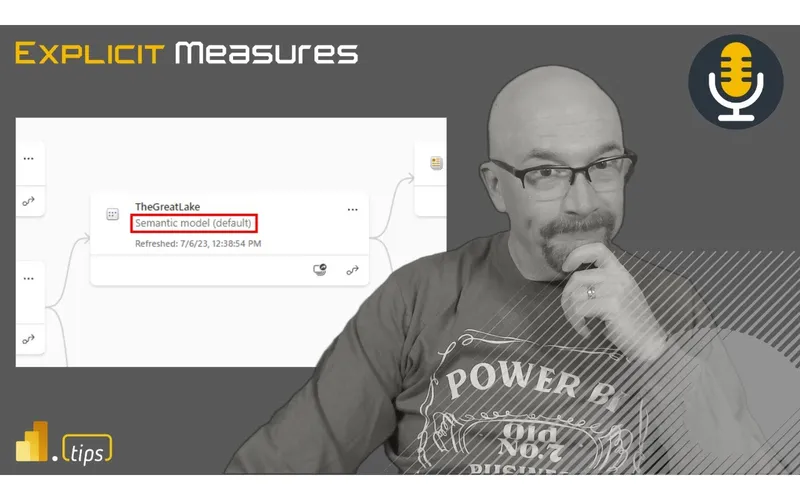
18:53 a feature not a bug where anytime we create a Lakehouse and part of the Lakehouse we get also a SQL Server Warehouse and part of that warehouse we get What’s called the default semantic model now this default semantic model is simply the by default the tables that are part of that Lakehouse where we can Define the relationships create the measures all in the service and by again without us doing anything without us blinking there’s always creation of a default semantic model for every
19:23 default semantic model for every Lakehouse that has a Delta table created now for us for who have been working in powerbi for so long and the idea of what a semantic model is and both the the user story in organization to individual creation this can seem initially to fly in the face to a lot of processes but what we’re talking about today is one is the default semantic model that is created after every lak
19:53 model that is created after every lak house the primary method that we should adopt and that organization to adopt should we completely ignore it what are the best or what are the good use cases for this default toic model why is it there and what are we GNA do about about it I don’t think I want to talk about like what is it honestly like we’re going to skim over that really quickly here and then get right into like okay what do we as experts who have done semantic models for a number of
20:24 done semantic models for a number of years how do we interact with it so very quick introduction to what is the default semantic model we we know what a semantic model is it was originally called a data set which now changed to semantic model which they’ll probably change back to data set in the next couple months because that’s what they do with goals so we’ll see what happens hopefully it stays put default semantic data set will be default semantic data set model everything else is semantic model everything else is good but look this is basically what this thing does is when you create a lake house you get
20:56 is when you create a lake house you get by default two additional artifacts effect that come along with the lake house the lake house has the place where you store files it’s it’s attached to one Lake the lake house is a files area and a table area the table contains Delta tables the default semantic model and a SQL analytics endpoint are immediately created every time you create a lake house you can’t turn it off you can’t not create them they’re just part of it and what I understand is this is how I read this the default semantic model immediately takes all the
21:26 semantic model immediately takes all the definition of every table in your Lakehouse and makes a direct Lake connected table inside this default semantic model and the default semantic model is something that you would use to I’m just interested in making a simple report on a couple tables that are in the lake house right or I need to make like a relationship and and make some changes to that default semantic model I think that’s about it for the explanation if you create another lake house you get another default semantic
21:57 house you get another default semantic model and it points only to that Lake house I don’t think you can add stuff to that default semantic model that’s not in the lake house it’s literally a one toone if you want a table in the default semantic model it has to be in the lake housee somewhere right yeah I think I think the two distinctions I’d make are you you there is some selectability of what you want to show up in the model and and most importantly the capabilities in the UI of the mo the
22:27 capabilities in the UI of the mo the semantic model experience are different between the default in custom right like and that’s where some of the biggest challenges I think come come in and why chat definitely has an opinion in this topic that’s already firing off which I love which is great that’s why do those those are the only two things I would I would say as well okay the let’s let’s let’s talk about it so what what are the what are the things that we like maybe we start with some of
22:57 that we like maybe we start with some of the things that we like about the default semantic model maybe we start there and then we’ll talk about maybe some of the edge cases of where it starts falling short of like our and again I think this is for me I’m thinking about how do I build stuff like what do I do when I build things from Models what do I do when I build inside the lak house my pattern for development is bring everything I can as much as I can to the lake house everything I’m doing is bringing data there if if there’s and this is one of the reasons I have a big gpe around data flows Gen 2 is because data flows Gen 2 incremental
23:27 is because data flows Gen 2 incremental refresh doesn’t not work with my Lakehouse plain and simple I’m like this is annoying to me I if I can’t bring the data to my Lakehouse it’s almost a non-us non-used tool and everything Microsoft is communicating as well is everything should go into the lake housee first and then you should work from it from there because it’s the Delta format is Now the default format for semantic modeling it’s now how you optimize and and make those tables efficient and fast and that’s how you use them in the model so to me the lake house is so important to what we’re doing nowadays it this has been the huge
23:58 doing nowadays it this has been the huge change of what we’ve seen with fabric versus non-fabric things the lakehouses is the massive game changer for me and I think another day too I actually have it as an episode two I know someone was talking even about the common data engineering workflows and how they’re predicting they may not be relevant in the days of fabric but I I pertain for that for another day but I think the default semantic model
24:28 think the default semantic model I’ll start with what I like because I almost immediately went to the frustrations yes let’s go yeah so it’s definitely it’s direct Lake direct L and that is such a plus and it’s amazing how well direct Lake can work so if I already have the creation if I’m already in powerbi service like I got my tables all right let’s some quick relationships in the service a measure or two and again this is it’s basically real time but not real time it’s not
25:00 real time but not real time it’s not this live connection still will have a save button somewhere save button yeah just my own AA thing but because we’re doing things we like not things we don’t like yet we’re we’re getting there I’m just mentioning that okay but the direct link and again this all happens in the service I don’t need another file y I don’t I don’t have another source or another location my computer to do this it’s all created there and once you start creating reports off of this the speed of this there is no refresh
25:32 the speed of this there is no refresh time there is no oh did you load that load the data from the report it’s immediately reflected whatever is in your lake house and there are settings that go along with this one right so when you when you up so that’s that’s a very interesting pattern that we’re seeing here which is new but it you can turn that off you can do some other things that there’s actually a whole another there’s a whole I went to a talk with Phil C Mark and Patrick LeBlanc around lake houses when I was at the fabric conference in Europe and I was
26:03 fabric conference in Europe and I was like oh it’s direct Lake refreshing should be easy no no no there’s a whole bunch of other technology they’re doing so yeah they’re bringing a whole bunch of tech in there this thing called reframing and refreshing and all these other things so it’s it’s interesting that you can there’s a lot of other technology under the hood here you can make it automatic or you can slowly change it when you want to so there there’s a lot more flexibility now with using the direct Lake connection to tables which is super cool I really like the the flexibility we get
26:36 there what else Tommy what else do you think you you like about it so I do like the ability to I can actually connect to that model in other services like a Azure data Studio you like the ability to start creating reports in powerbi desktop real time is that lightning speed of that it’s really great but honestly though when it like I said I want to go immediately to I don’t want to say the worst negatives in the world but I think it’s important unless you have more things you want to add to the like side
27:06 things you want to add to the like side of of things let’s give Seth let’s give Seth a run at this and say Seth is anything that you are as we as you look at the semantic model the default one are there things that stick out to you are things features that we didn’t mention already that would be above and beyond items you would point out that we should we should take note of I don’t think they’re far off from the intent of or the purpose for it right if it’s if I’m building objects in a lake house and I’m I’m shaping them and creating my facts and dimensions as they would appear
27:37 and dimensions as they would appear right like from from getting to Raw data or the structures of that ETL and framework to shaping something that gets pulled into a model like it makes it makes sense like like that oh man like I don’t I don’t even have to go through the steps of provided I’m carving just a part of part of like the tables I don’t I certainly don’t need everything and I don’t want everything to be pulled into the model so sure if I can hide it or not it can’t be part of that which I can like that
28:09 be part of that which I can like that that cuts out that whole other layer of like management especially with the sync and like as I’m making changes as you and like as I’m making changes as like as you’re adjusting and adding know like as you’re adjusting and adding business logic and adding the other column and like all of those things just like filtering forward and being available in the model like so from the data engineering perspective I think it does what it what it’s intended to do I think the challenges come after that where like you you’re you’re hamstringing some of
28:41 you you’re you’re hamstringing some of the capabilities of the modeling experience sure and that’s just not acceptable for like like the semantic model Builders and Report Builders right like that’s where the conflicts are going to come in and I think rightfully so I agree with you on this one I I think so I think I understand why they put it there I think what what I feel like is
29:05 there I think what what I feel like is happening is they’re showcasing the ability of look we can automatically create semantic models without having you to import everything I think that’s the really the Showcase here to me the Showcase feels like that is the reason why they’re they’re doing this automatic here’s a pre-built model here’s all the tables that you think you need which is awesome it definitely helps I would also argue if I’m using direct Lake and I just need to go check out some inside a column it’s actually more efficient I can build a couple relationships now I’m going to start moving into where Tommy was saying like there’s some gripes
29:35 was saying like there’s some gripes about this right it doesn’t default the default semantic model does not create relationships for you automatically so you make a bunch of tables it’s not going to either one Auto detect them but it actually requires you to go back into the tables in the and this is where I think it gets a little bit weird if I’m in if I’m in the in the direct Lake and I’m trying to edit this default semantic model you don’t actually edit the default semantic model you don’t go there to edit it you actually go to the SQL analytics endpoint and then you edit the default semantic model which I think
30:05 the default semantic model which I think is a bit weird in my opinion if I have the list of tables and I have the list of the model and I’m going to create measures or do things inside that model I’m expecting to do it by just saying edit the default semantic model and I would me personally I think the UI makes the most sense to just say I’m going to do it in in the modeling side the model is where I would do this granted there’s no Pages fine don’t care but if I create another semantic model something that’s different the whole UI is slightly it’s
30:35 different the whole UI is slightly it’s slightly different like the UI is different there’s there’s other other buttons there’s other things I can do I think to your point Seth right if I’m getting that rich editing experience somewhere else I would really want the default semantic model to have all those properties now let me let me ideate a little here on top of this right the default semantic model is great I’ve got tables I can build relationships I’m want to ask the question here I can build I can’t build measures or I can build measures you can you can’t build calculated columns or anything
31:05 calculated columns or anything calculated columns because that’s the direct like limitation there but you can start slipping in measures and things in there as well I feel like I’m not finding them actually have the application open I’m not seeing any place where I’m adding measures here maybe I’m missing something no you you can can but it’s yeah it’s not if you’re in the if you’re still in the warehouse view you can’t so you relationship so how you have to create you can create relationships in the in the warehouse so
31:36 relationships in the in the warehouse so this is this is where I’m like a little bit mysterious right so I’m going to step back up not talking about the tool technology for a second let’s just step up a moment we have this idea or concept where we work with companies and it’s this idea of the master and the Mini model right we have this idea of these are our main data tables dimensions for for dates dimensions for people dimensions for master product right we’re going to make those tables and we’re going to put them in the lake house we’re going to have a number of fact tables that may or may not join with all those Dimension tables we may have multiple fact tables and so we
32:06 have multiple fact tables and so we could think of like a manct table star schema that we’re starting to build in The Lakehouse I really think this is a opportunity for Microsoft to say look the default semantic model is where you define the master of everything this is where we bring all the calculations all the dexs all the things into that same that singular model and then you should be able to make let’s call it for lack a better term a child semantic model right from the main one I make a sep I make a
32:36 from the main one I make a sep I make a copy basically and I think you can do that today right you can take the modeling that’s been done in that main Master model and you can say create a new semantic model if you do that I would love it to bring all the measures all the relationships all everything that I’ve been working hard in the default it would be nice if it would take a copy of it and then basically build me another semantic model that has all the main features and let’s think about this I would love it if I need to go at measure
33:06 would love it if I need to go at measure if I’m going to go add a table I would go back to the default semantic model and then I would say okay I’ve made new things in that default semantic model what of the items should I be pushing either relationships or measures and it should be that is the source of Truth the data dictionary of what I build my data to be looking like and then from there I build a handful of mini models master and Mini model this is this is one that Michael kovalski does a lot of where he talks about like the master
33:36 where he talks about like the master Mini model perspective right I’m going to give a a set a subset of tables and things there Michael in the chat you you bring up a great Point here like a perspective yeah it feels like a perspective it’s it’s the same model but it’s not the main model it’s it’s like a version of it somewhere else so I think I would like to see that and maybe this is where is where Carly has done a YouTube video with us around the metrics Hub and Metric hub’s amazing and I think this is
34:06 hub’s amazing and I think this is maybe where is where the metric Hub fits where the metric Hub gives you the large default semantic model and you start carving out pieces of it for other or people in the organization to use so that’s my big picture comment I’ll just pause there I said a lot reactions Tommy and Seth so you make a really good point when it comes to the metric side of things because I think this is a relatively new documentation when Microsoft did announce the made some major updates to the one Lake documentation but they’re saying the default semantic model is going to
34:37 default semantic model is going to provide that ability to create standardized metrics that can be used for repeatable analysis so because we don’t have that yet we’re not seeing that major feature or that impactful feature actually the weight of that right now right right now it feels like it’s just simply a dumb down vers version of model creation but because again it’s not meant to be the like the normal soup nuts model creation especially especially if we’re going to
35:07 especially especially if we’re going to be dealing with this idea of metrics that overlap across models so a lot I think of the features that really make the semantic model Stand Out are I don’t think as available yet but that is interesting you say that I I it’s interesting yeah I I don’t I think it’s a bigger leap going your direction than than mine which would be is if the defaults going to end
35:37 would be is if the defaults going to end up to be the master like there’s a lot of stuff that needs to happen there’s a lot of missing things I need to build right including including the the total wrong direction where the default should not be throw everything in the semantic model because that’s the most horrible practice in the world right because it is specific Limited in scope and you need to like in this case relationships matter like how you set that up structurally is extremely important and
36:07 structurally is extremely important and and I think there’s even some chat going on where people feel strongly about wanting to build that themselves because there there are key components that if not created right go Ary really quickly where I do see value in this I guess is almost from like the dev persp perspective right I I would still think that being able to select the objects I want to pull in right that should be a default experience as opposed to you assuming I want everything everything I
36:38 assuming I want everything everything I would agree with that St at the same time like if if this is autocreated like now I have an extensible way of like testing the entire pipeline right like I’ve created these Dimensions there they’re in my model I’m building these relationships I want to just validate the data in the report area right and to me like okay I I can see the value in like skipping some of this or as I’m making those changes Auto apply them and all of the sudden I I get to my my final Place
37:09 sudden I I get to my my final Place faster from I’ve got some basics in in my model and I validated all my numbers like to me that would be a useful where where I fall apart was like to and and I know technologically speaking right like there are limitations to this default fault if it’s the test bed let me let me take what I’ve tested or configured and and save it as a custom because now I want to extend on it now I want it to be
37:39 to extend on it now I want it to be something that I can have the full capabilities of what the UI gives me at least in in that case because I I don’t think it has everything that the desktop has or some of the things that you can do in Alm toolkit related to like semantic models which corre I it’s pointed out by James in in the in the chat so like if it if it’s going to become the model that we use and and we’re far away from those features like let me save it into that realm where I can utilize all those features yes then
38:11 can utilize all those features yes then it becomes extremely useful from my perspective because it’s streamlining some of that back and forth testing the iteration the like the things you have to create anyway and if the default is nothing other than the stepping stone for me to get to my final model faster cool right but if I have to go rebuild everything after the fact then it’s not not not as cool Les it’s less
38:41 it’s not not not as cool Les it’s less it’s less useful it’s l I agree I totally agree and this is I think the hardest part for most people in terms
38:48 hardest part for most people in terms of if we’re actually going to have a governance story around this or really that true that true adoption and again there may be some technical reasons why that’s not a available now but yeah like all the events tooling Tabet editor can connect to a semantic model in fact that was created off of a data or lak housee but it can’t connect or save the default semantic model that all has to happen to the surface yeah there’s no way to recreate what you did on that default centic model and again that that leads
39:20 centic model and again that that leads to a lot of extra work I might Seth the idea that if we could do that quick testing and have almost create like this Baseline that everything else would be created office I love that idea because just not just not available yeah but I think that’s my challenge though a lot of this is like I I get a lot of what I think I need but I think I need like there’s no way and there’s also no way to do a diff like let’s say I I add some things a relationship a new table into the default semantic model and I carve off
39:50 default semantic model and I carve off another model that I’m going to to your point south enhance enrich do the thing how do I know what has changed like it’s just another cop of an artifact so there’s no lineage there there’s no really there’s no no value of like so to me it just cuts off the value for me like why then why would I want to spend a lot of time building default semantic model I’ll just build a custom one and then I get all the features I need I get everything I want and I and I don’t worry about it yeah and sometimes I wonder you you it yeah and sometimes I wonder you sitting on the dark side which is
40:20 know sitting on the dark side which is we’re not part of the plan we don’t know like what the the the total vision of default semantic models is but yeah it’s the communic part and like so either I’m stuck with whoever developed this doesn’t know Their audience and didn’t engage with semantic model builder right and it’s just a miss or it’s they did and there’s a course set what is the bare minimum core set of functionality we can put out the door and then we’re going to put out the door and then we’re going to build towards what we want it to be I probably that
40:53 what we want it to be I probably that it’s probably that at the same time it’s just like it’d be nice to know what the road map items are and maybe they’re out there somewhere and we just have to go go digging but I’m going to blame I’m going to blame us I’m gonna say Microsoft has a beautiful vision for this and it’s just it’s just us not finding where the road map is it’s probably it’s probably us exactly right but I agree Seth I think your observation is incredibly accurate there I think it was a I feel a lot of the features that we’re getting right now on fabric is a we need to continue pushing
41:23 fabric is a we need to continue pushing some features out the door I think we’re in this place where a lot of things are new we’re in this Death By A Thousand Cuts most things work very smoothly but there’s a lot of like UI experience things that are still a little bit rougher on the edges and so I think this is a lot of Microsoft they did this with powerbi they pushed out a ton of features and saw what was the usage on those features and then the features that have a lot of usage gets the funding to build the next feature for that that item so I think this is another one of these cases where a lot
41:53 another one of these cases where a lot of features are going to get built in Fabric and you’re going to see some of them get to a point of it’s mature enough to get it working and people can use it may not be super smooth but they’re going to they’re going to step back and they’re going to say what is the usage on all these features and if it gains a lot of usage then they’ll invest more time to build more features that’s software development 101 that’s epev epev 101 except for the I would agree with you because let’s all poor one for data Mars where that obviously was maybe the precursor to this but if I if I’m not
42:26 precursor to this but if I if I’m not mistaken especially the direct Lake mode if I connect to a Lakehouse or the warehouse from powerbi desktop that’s not direct Lake say say it again so if I’m in powerbi desktop where another tool and I connect to the warehouse of just the tables not to the default semantic model that is not direct Lake mode no but you can go from desktop and go to the lake house and suck in tables that are direct
42:56 house and suck in tables that are direct Lake Lake correct the SQL analytics endpoint is just a SQL SQL endpoint it’s like a SQL Server so and I think the the direct Lake mode for the reporting I believe only works with the the default take model because if I’m if I have to take okay you can go get direct Lake tables in desktop now Transformations but there but you can do you can build other stuff now you don’t have to build from that one moving forward or you can go to the default semantic model and say create a new semantic model off of this you pick
43:26 new semantic model off of this you pick the tables you want and then you get another semantic model that has direct l so you can do it in the service also you now you can do it desktop and this again to your point SE earlier right they they landed this the reason I think default semantic model showed up was because there is no other way to get direct Lake tables working other than the default semantic model or starting to build it inside the service so you had to start there so I think there was an idea of like you needed it there just to start using direct Lake now that we have other ways of creating direct Lake enabled tables I think the default semantic model is less impactful it’s less ful
43:58 model is less impactful it’s less ful yeah it’s good for some self-discovery maybe it was the stop Gap to showcase the where they’re going to go with it l Lake while while it was the capabilities were built into other tools or built into the other custom ways we can build some antic models what let me step back a second what I’m ask a question here is what if what if we had the ability what if all the editing that we get for normal like when you create a custom semantic model would you change your mind about the default semantic model if that
44:28 the default semantic model if that experience of go to the model edit the model and get all the details of the model if you had a different experience around that and that was what you if you had that editing experience just the same way that we have the default semantic model today and replace that experience would you would you would it change your would you use it more potentially but I probably not no okay Mike you talked about the the purpose of the lake houses I’m pulling in all my data well I may
44:59 I’m pulling in all my data well I may not need from a single Lake lake house that that’s all the data I’m going to need because I may be pulling from other places or a particular centic model may require some trans additional transformations to be done for that model doesn’t matter Transformations is no you can’t transform anything anyway like if I was going to do any Transformations I’d have to go run a notebook pick up the data put it back in anyway so yeah it doesn’t to me transformation by the time I’m hitting default semantic models there’s
45:29 hitting default semantic models there’s no Transformations you’re done the the data is shaped the way you need it to be shaped no I that I know but I’m saying a lot of times when I’m creating another model or you we’re creating models off of standard tables like in the whole world that we’ve had before fabric right okay you yes but that was all power query if I’m doing that transformation stuff I’m doing that after like I have a table and then I produce my Transformations we’re saying all of that is done before I get to the table so you’re doing that
45:59 I get to the table so you’re doing that in bronze and then I’m going to silver or gold and I have the final tables the way I want them so there should be no Transformations needed on those tables if I do need it I’m going back Upstream to build it in the engineering side of things yeah maybe a little off top but I’m talking about diff every model that we have may have some unique things for that model not for the business data where yes we know the we have done the Transformations we have combed it cleaned it done everything we need interesting you say that I would
46:29 interesting you say that I would assume every model is unique because you wouldn’t need another model I why would I want to have the same model multiple times there’s no reason to do that like every model should have some unique flavor to it if you’re building if you’re building the same model many times you need to step back and say what are you doing are you really are you’re wasting your time maybe you should just think about one bigger larger model that contains all the things you need or maybe your design of these edge cases are not really valid so maybe there’s use cases there that that are doing that but I would assume the reason you’re building other semantic models is
46:59 building other semantic models is because you need some different table structure or different data that does not included for different audience I’m I’m thinking a lot less about like tables and building tables and things for a particular report now I’m thinking a lot bigger now in these now that I have the the fabric space I’m thinking more like what does the what does that team need what does that Enterprise solution need how do we make it easy for them to consume the model I think that’s my point though those reports or those custom views of the gold data is not going to go away where
47:31 gold data is not going to go away where someone’s like hey we want a first customer analysis Journey View thing where that’s not really something that would live in a Lakehouse the group Group by first customer and yeah you would all I would live in the lake house 100% you’re not going to there’s no reason why you wouldn’t do like if you’re doing grouping by weird things things there the fact that we can do the engineering of the data much so this is where I think we’re going to differ a little bit is the semantic model because we have all the horsepower of notebooks and data flow Gen 2 and now pipelines
48:04 and data flow Gen 2 and now pipelines we now have the ability to shape the data way further like right now right in front of the model so our models should get simpler if the data structure of the tables in the model aren’t efficient for the semantic model to run efficiently I’m going right back to the data engineering side of fabric and just building what I want and making and shaping it so to me the data engineering portion of this is getting much more important and I’m pushing back a lot harder on people who are building complex models and tables and
48:30 complex models and tables and interconnected things to get the visuals to work I’m like well no step back if we need to build aggregation tables we have all the raw data right there yeah a ag the table just do it in the back end it’s faster it’s going to be more efficient and then it’s always prepared and you’re not having the calculation engine running over and over and over again doing these like really complex calculations build it into the model like so to to me I’m I’m more apt to making more tables that are delivering what I need as opposed to more complex
49:01 opposed to more complex DXs I don’t know where this has anything to do with the default model in general I I I agree with I agree with Mike like I think the the whole premise of fabric is bringing your data to the same place and having structures that follow the same patterns if at all possible and I think a lot of those are being developed in reshaping how we generate the models and the reports than we were before or at least it gives us the path from folks that are pulling from all these disparate sources and saying okay let let’s just simplify
49:32 and saying okay let let’s just simplify this whole thing this is now how it works in our ecosystem yeah right we’re going to put these random files here we’re going to create these objects and all of it gets sucked in the same way this is much more performant it’s much better blah blah blah blah and we can extend further to to answer your question though Mike I I think if the if it wasn’t a different experience and you were just giving me an accelerator MH MH mhm then that solves my use case right like because what I’m saying is I I see
50:02 like because what I’m saying is I I see it as an accelerator to get to where I want it to go if it’s the same interface and the same capabilities and the same everything and all you’re doing is just streamlining some of the the orig the initial build yes yeah love it yep and let me go back like so let me give you the one I know we’re get we’re running out of time here but so I’m going to end with my final thought here on this one because I think people got meetings and we got to do like real work we can’t just talk about powerbi dat engineering all day long so we we’ll move people along here but my major gripe with this one is right
50:33 major gripe with this one is right default symetric models are helpful they definitely utilize a lot of really good easy to use it just shows up you make your lake house boom stuff is is there great good for initial exploration things but outside of exploration I’m not really a big fan because if you even go from so a lot of things that I’m doing now is look teams are getting bigger we need a minimum of two environments a Dev and a prod minimum because there are developers building things or changes to models and I can’t release what the developers are building to a team of people Department team
51:06 to a team of people Department team Enterprise CTO whatever that is I can’t break their reports so I need some physical separation between what I’m developing and what I’m actually making so deployment pipelines are awesome I love them when you have a default semantic model because the Lakehouse is the only item that defines the artifacts when I go from Dev to test none of the metadata that relationships any measures I build anything that’s inside that model I only get the tables that have been loaded into the lake housee so going from Dev to test the lake house
51:38 going from Dev to test the lake house comes over the name of the lake house is the same you you can deploy that through the environment but that’s it nothing else comes with it and so the fact that nothing it’s basically regenerating a brand new default semantic model and the the deployment pipeline process really is move the infrastructure to the next environment move the code pipelines notebooks move the code to generate the data and then you have to run or execute a load of data to actually hydrate the lake housee with information in it and
52:09 lake housee with information in it and only at that point do you get the default tables that come out of the Lakehouse so to me because I can’t move any other designed artifacts with the default semantic model to the next layer and again I agree this is a hard challenge how do you solve this how can you move a semantic model to the next layer if there are no tables there where where do the relationships attached to there’s nothing it doesn’t make sense so to me there’s there’s other things here that are going on like you’re never going to get the default semantic model because it’s trying to Auto build off of whatever is in the Lakehouse it’s just not going to be the tool that I want
52:40 not going to be the tool that I want really what I think and there’s another article here from Reza that was talking about this as well he makes the argument also use the custom centic model because you can change it you can you can save it to to the workspace you can get you can put it in G and then you can move it to the next environment and when those tables show up then the default semantic model or then your custom semantic model will have all the details you need that’s what I want that’s really that I don’t I don’t at this point I think we’re getting we’re walking farther and farther away from needing the default semantic model it’s just not something
53:10 semantic model it’s just not something it’s just there for exploration I don’t think you’re going to need any moving forward I think you’re going to just focus only on building custom moving forward at least that’s where I would put my eggs in that basket very long final thought Tommy any final thoughts for you no I I I think the biggest thing is as we continue to move forward with a lot of the new features coming in fabric there’s definitely the way we’re viewing semantic models or how we view semantic models is is changing the the El
53:41 models is is changing the the El elevation of things in the service and really I think this is going to go in perfectly in line with the metrics Hub and the importance of that more than the model itself so we’ll see when that comes anything Seth for you any wrap up thoughts here when’s the last time you used something any any when is the last time you used a default anything in in technology that’s a really good question I I I think I think I see
54:14 question I I I think I think I see the vision I think it is going to go in one of either your direction or or mine I hopefully it’s a useful tool to some degree I think there are too many drawbacks of where the limitations on the front end are going to prohibit people from even engaging in it early because it it doesn’t serve the ultimate need so Pathways to either it being the full full solution right or it being more of a testing bed to to
54:44 it being more of a testing bed to to build a custom semantic model remains to be seen so it’ll be interesting to see how it evolves over time but for the time being like yeah I would recommend sticking with the custom it feels like it’s some level I know that the default centic model’s probably woven into a lot of the Microsoft parts of things it feels like I don’t know if I would do this for the SQL analytics endpoint it feels like I want to switch create lak housee with default semantic model or not with default semantic model
55:14 model or not with default semantic model I I think it’s I know it’s there I know it just works I don’t think it costs me anything extra in compute usage if it’s there but I I actually think you if it’s there but I I actually think if I’m trying to make my workspaces know if I’m trying to make my workspaces really clean and not make a lot of extra clutter this would be one of the things I would actually want the option to turn off I do like the Lakehouse I do like the SQL analytics endpoint those two I think pair very well together I don’t think I need I don’t think I need the default semantic model I get it but what is the semantic model in in its base form it it’s just alleviating the connections alleviating the connections
55:46 connections alleviating the connections to the to the the lake house tables right and in that connection mode and it’s it’s that that Hive right that just goes okay this this is the thing that’s going to ease a workload along along the way because then you don’t have to do that and I think the feedback is well we’re going to do it anyway because there’s not enough integration in the point that we need it my comment to that would be is is as a what if what if we just said screw it we don’t need default semantic models and we don’t need lak housee the nobody
56:18 and we don’t need lak housee the nobody wants nobody wants your semantic model just just give no no just give me the lake house I think I think there’s maybe an option here that says just give me the lake house I’m trying to keep my environment clean I don’t need those two other items they’re not required no I agree I the default stuff drives me nuts like it if I can’t remove it I don’t want it yes obviously right that’s true yeah I I to me the the L Lynch pin for me is the lake housee lake house is incredibly important yeah the things that are coming default not so have about it and and honestly if I’m going to build stuff I’m going to build my own
56:50 to build stuff I’m going to build my own SQL analytics endpoint I’m going to build my own Ware SQL Warehouse in there I’m going to build my own default semantic models that’s what I’ll do and but I’m but I’m not a beginner developer anymore right I’m I’m a pro user right we are the the experts in this space so we were saying like of course we’re not the experts don’t use the default stuff new new users probably will love it all right with that being said thank you all very much for your time this was a great episode we we appreciate your ears and you’re listening to us for a whole hour as we Yammer on about something that probably the only like 5% maybe even less 1% of the world even cares about so we hope
57:21 the world even cares about so we hope your run or bike ride or something that you were doing today was a productive good job for getting to the end of it or quitting early and staying on the curb and crying because you could a to finish your workout but that being said please share this podcast with somebody else we appreciate your ears we appreciate you jumping in and listening to us Tommy where else can you find the podcast you can find us on Apple Spotify or every your podcast make sure to subscribe and leave a rating it helps out a ton you have a question an idea or topic that you want us to talk about a future episode head over to power. tisp podcast
57:53 episode head over to power. tisp podcast leave your name and a great question and finally join is every Tuesday and Thursday a. m. Central en jooin the conversation all of powerbi tip social media channels almost didn’t make it there thank you all very much see you next time next time [Music]
Thank You
Thanks for listening to the Explicit Measures Podcast. If you enjoyed the episode, subscribe on YouTube and share it with a teammate.