
Let me setup a scenario for you. You get a data file from an automated system, it has the same number of columns but the data changes for every new file. Being the data savvy person that you are you’ve spent some time working in excel to make a template where you can copy your new data into and then automatically all your equations and graphs magically work. You pat your self on the back and happily send out your fantastic report to everyone you know. Then tomorrow when the data comes to you again you repeat the same process over again. Still enamored by your awesome report, you send it out again knowing you have saved your self so much time not having to do the analysis or creation of your reports over and over again. Now, fast forward 3 months. That stupid report shows up again, and now you have to lug all that data from file to file and begrudgingly you sent out your report. Thus, is the store of the analyst. You love data, but you hate it as well. Well in this tutorial I’ll show you how to remove some of the pain of that continual data loading process by loading new data from a folder.
My previous post (found here) talks about loading data from a folder. In this tutorial we will add some logic to this method that will look at a folder but only load the most recently added item from that folder.
Data for this tutorial is located this link Monthly Data Zip File. This data in the ZIP file is a monthly data sample from Feb 2016 to April of 2016.
Download the zip file mentioned above and extract the Monthly Data folder down to your desktop. Open up PowerBI Desktop and click on the Get Data button and select All on the left side. Click on the item labeled Folder and click Connect to continue.
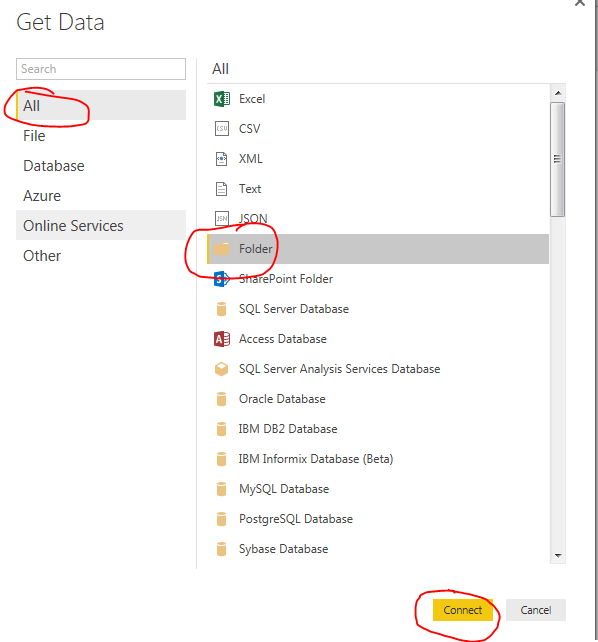
Select the newly unzipped Monthly Data folder that should be on your desktop. Click OK to continue. Upon opening that folder location you will be presented with the multiple files. Click Edit to edit the query.
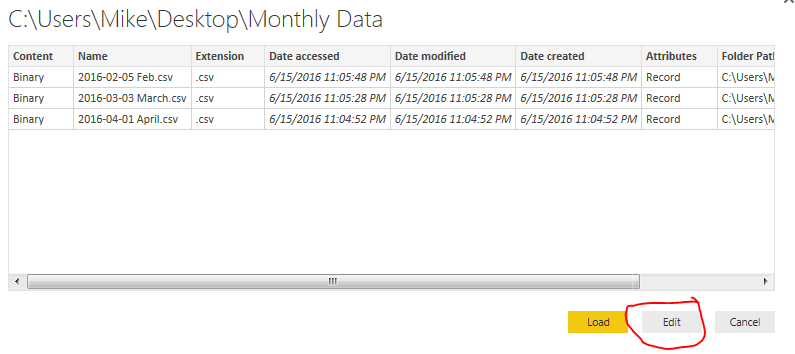
Now you are in the Query Editor. This is where the fancy query editing will work to our advantage. We could load all the data into one large query. However, depending on the size of your data sets or how you want to report your data this may not always be desirable. Instead you may only want data from April, then May when the new data is sent next month.
Thus, our first step to start pairing down the data will be to first filter the files in sequential order. In this case because I have named the files with a Year-Month-Day format I can sort the files according to their names.
Note: When using PowerBI desktop it is a good practice to name the files beginning with a YYYY-MM-DD file name. This makes it really easy when sorting and ingesting information into PowerBI. I have used other columns of information such as Date Accessed or Date Created before but have gotten inconsistent results as these dates can change depending on when a file was moved or copied from one place to another.
Click the drop down next to Name and sort the files in Sort Descending.
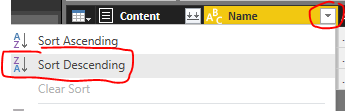
This places the files with the most recent file at the top of the list.
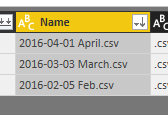
Next click on the Keep Rows button on the Home ribbon, select Keep Top Rows.
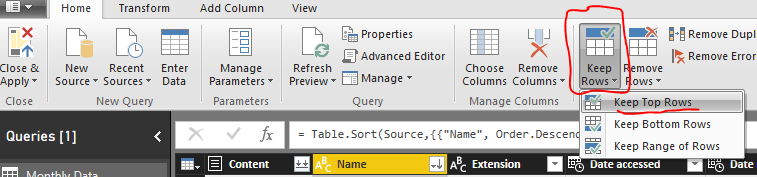
Enter the number 1 when the popup appears. Click OK to continue.

Now you’ll notice you have only one file selected which is our latest file from April. Click the Load File button found in the Content column.
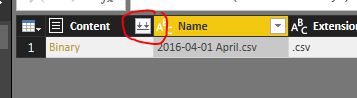
We have completed the activities in the Query Editor and can now load the data. Click Close & Apply found on the Home ribbon. All our April data has loaded. by making a simple table we can now see all the data that was just loaded.
Now we will remove some data from our desktop folder labeled monthly data. Open the folder on the desktop labeled Monthly Data and delete the filed labeled 2016-04-01 April. You should now have a folder labeled Monthly Data with only two files in it, one for Feb and one for March.
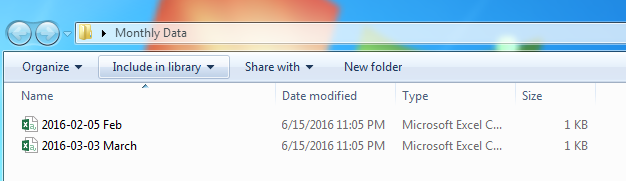
Return back to Power BI Desktop and click the Refresh button on the Home ribbon. Notice now how all our data has changed. We are now looking at the March data because it is the most recent file in our folder based on the file name.
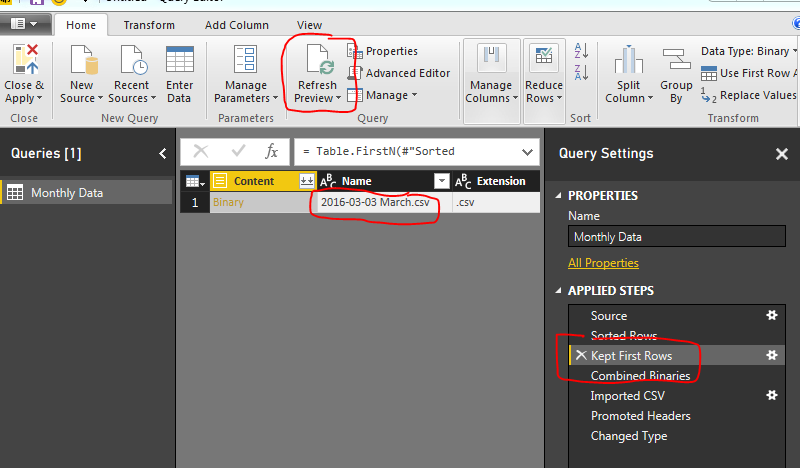
To verify this we open the query editor (Click the Edit Queries on the Home ribbon). Click Refresh Preview on the Home ribbon and finally select the Applied Step called Kept First Rows. This will reveal the month of March as our data source.
Now, every time you add a new file to our folder and refresh PowerBI the latest file (based on the naming convention we talked about earlier) will always be loaded.
Note: This method works great when your data source is coming from an automated system. The file format must always be the same for this to work reliability. If the file naming convention changes, or the number of columns or location of those columns changes then the query will most likely fail.
Good luck and thanks for following along.



Again, Great article. I really enjoy learning from your examples. This shows how we always have the most recent folder but what if we wanted the accumulation of the three months Feb March and April and NOW we have May and we want to add that file to the folder so now we have trends showing all four months ad so on as we get more monthly files to add to this folder.
Is it possible to have a slicer for the folder. For example i have daily and monthly reports for different projects lets say P1, P2 etc. And inside i have mulitple folders with error report, productivity report, timesheet etc. I want to have a slicer selection for the folders? Is this possible?
In a simple term yes you could have a slicer for the different folders. However, in order to implement this you would need to load all folders. All the data would load for all folders into the report. I think this possible, but would get complex in the query editor which would require writing functions to load all the data in each folder. Instead you may want to use a parameter with in the query editor to select the folder you want to load. This way you can edit the query pick your folder, refresh, and the data will load from the appropriate folder. I did something similar to a parameter in this tutorial. This would be the easiest implementation of loading different folders.
Hi, great article. In Windows 8 and 10, we could add more columns to a folder, eg. for picture folder, we can have the camera model, date taken, etc columns added.
I would like to include this additional columns into the get data from folder option, but it seems to fixed to the out-of-box columns only. Can you advise if we can configure the system to include these additional columns?
Albert, great question, as far as I understand PowerBI today, the only folder columns you are able to retrieve are the default ones that PowerBI detects. I am not aware of any configuration that can be changed which would give you additional columns during the file load.
I found a typo:
We are NOT looking at the March data because it is now the most recent file in our folder.
Should be:
We are NOW looking at the March data because it is now the most recent file in our folder.
Vince, you have a sharp eye. Thanks, I have updated the post accordingly.
Great Job.
I wonder if there is a way to tell Power BI: ‘Hey, i do want to load all of my monthly files; however, refresh only the files that have been modified’.
This would improve my refresh latency from >40 min to less than 2 minutes.
Any ideas?
Thank you all!
I am not aware of such a function. However, If I were going to solve this kind of problem here is how I would try to do this. I would make two queries one that loaded all files with a changed date greater than one day. Then a separate query that loads files which have been changed within the same day. Then create a third query to join both queries together. This might speed things up, but what I don’t know is if you can request to refresh only one query on load time. You’d have to test that out.
Great walk-through! Concise and easy to follow.
That said I am running into a frustrating issue. I keep getting this error when I attempt to refresh with new files.
Expression.Error: The key didn’t match any rows in the table.
Details:
Key=Record
Table=Table
The file names follow the same naming scheme (YYYY-MM-DD_HH.csv) and the tables within all have the same columns in the same order. I’ve experienced this on multiple computers all with pretty current desktop versions of PowerBI. I’ve read about little tricks like going to the query editor and hitting the Refresh Preview on the step in question. This has not worked for me. It appears the issue occurs when I load the content, right after save and close. Some steps are added, namely the step “Expanded Table Column1” is where it fails. Any thought?
Thanks
I think what is happening here is that the data inside the files might not be following the same format as the initial file. I would suggest try removing all the files except for one. See if the data loads. Then add one more. Check to make sure it is still loading, then start adding more and more until you find what breaks the query.
Microsoft has updated the loading data from a folder dialog box so this now has a more streamlined interface. As an alternative update your Power BI desktop to the latest version and trying loading your csv files again using the new dialog flow.
I recreated the same steps as above and I am hitting a snag.
WHen I delete the most recent file so that it will go to the next most recent file (Sorted by date) it continues to look for the file that I deleted rather than updating to the new recent file.
I think I know where your having the issue. I believe it’s after the step where you keep the top 1 rows. When you do this there is a link in the Content column called Binary. If you click the Binary link, Power BI Desktop will hard code a file location to only that file. Instead, Click the Double Down Arrow icon (called the combine files button). This will open up a new dialog box, which was added later on to Power BI Desktop. Select the sheet of the excel file that you want to load, and in the Example File make sure the selection says “First File”. Click Ok to load the data. This will bring in your most recent file. When you remove your latest file and refresh the dataset, the Power BI Desktop will pull the most recently dated file.
Mike, that was so easy to overlook. After going through that step again paying attention to what you mentioned – it worked.
I went through and through that several times originally without progress.
Thanks!
Super helpful! I was stuck for long on the step where the files metadata was listed and I didnt know how to load the file content. your article was a life saver. Thanks
Hello everyone!
I am a newbie in power bi and have a little query regarding refreshing excel data.
Is it possible to load the most recent data without disturbing the calculated columns.
I have created a pbix file where I have data table for 28 dec’18 along with calculated columns which i created to get some calculations like efficiency and machine utilization.
How to replace 29 dec’18 data with the existing data without removing calculated columns.
thanks in advance.
Yes, this is possible. Inside the query editor the data will load exactly the same. In order to not break your calculated columns, the new data your loading must have exactly the same naming scheme. If that holds true things should work with out breaking.
Hi, my problem is very similar to the problem discussed over here , just there is an addition to this. Usually the process has to run by picking up the latest modified file, but it should also throw a option to the user to select any file from the folder in case he changes his mind. Is this possible in Power BI?
This is not possible at this time. If you want options for users to pick a file, you would need to use parameters for selecting the file, and save the file as a PBIT. PBIT, Template files are by default without any data. When they load the are automatically prompted for the user to enter the file location.
If you want the process to be automated or automatically refreshing, then only the latest file can be selected. In this case I would remove the unwanted files, thus defaulting back to the required latest file. Then reloading the reports.
Sorry, from what I understand of your description at this time I am not aware of functionality in the program that allows this.
Thank you so much for this post and for taking the time to answer all the questions from your readers. 🙂 Keep up the good work!
First off, thanks for such a useful article. Really helped clarify what I was trying to do on my own.
Second, is there a way for a user to take a file that is being brought in by the folder import and turn it into its own query so it shows as a separate data source? Basically, I’m wanting to exclude a specific file from the import while still storing it in the same folder and bring it in separately as it throws off my visualizations.
Thanks again!
I would recommend loading all the items in the folder. Then right click on the Query and create a reference Query. Do this twice, once for all your normal files, then again for the stand alone file. Then for each query use the filter options on the file name and filter out items that are not needed. I would use filter that has, Text -> Does not contain filter context. This gives you more flexibility on selecting a word or multiple words within the file name to filter out or in.
Hi
I want to pass a parameter in which is the folder path where the user has stored the files, because each user hold their files locally and they download the latest files from an external location. So when the user refreshes the data the parameter requests them to in put the folder path.
Thank you
Good thought, you will want to follow this tutorial on how to do exactly that: https://powerbi.tips/2017/03/using-parameters-to-enable-sharing/
Thanks so much for the information.
I do have one complication that I can’t seem to overcome, not only does the file name change on a daily bases, but the sheet name changes as well to match the name of the file. Is there a way to over come this?
This can be handled by more elaborate code written in M. Likely based on your scenario you would need to write a custom function in M to handle this. Learning to write an M function is a bit more than a response in a comment thread. I would recommend getting a book that would definitely help out: Collect, Combine & Transform in Power Query by Gil Raviv Gil is an amazing MVP and has an excellent book on this topic.
I am currently working on a dashboard and I need to create a backtracking feature wherein the past reports (reports from January, Feb etc) can also be seen and I don’t know how to implement this. Do I have to create a database for this to store the data of the previous reports? Or there is another way to solve this?
From what this sounds like, you are taking snapshots of data and then allowing users to view data in the different snapshots. Typically this would be referred to as slowly changing dimensions. To handle this in your data model, you would like need to add a Load date with each file you are loading. This way you can select the time period you want to view the snapshot. Doing snapshots within report is much more complicated and requires a more elaborate data model.
What would be the best way to access automated files in the below folder/sub folder format? Keep in mind every new month there would be a new month sub folder created that contains new data.
W:\Network Folder\2019\2019-04\Labour Report\Daily report(Day 1-31 individual excel files).
W:\Network Folder\2019\2019-05\Labour Report\Daily report(Day 1-31 individual excel files).
W:\Network Folder\2019\2019-06\Labour Report\Daily report(Day 1-31 individual excel files).
For ease of automation, I would recommend the following. First, I would suggest moving your files to a SharePoint or Azure Blob storage location. This will ease the ability for files to have a scheduled refresh. Here is a good article to follow: https://powerbi.microsoft.com/en-us/blog/combining-excel-files-hosted-on-a-sharepoint-folder/
Then, if you can put all the files into the same folder this would simplify the data extraction. You can iterate through all the folders but this increases the complexity of the M Code. If you can name the files similar to the following 2019-06-17_data, and then the next day’s information to 2019-06-18_data, then you’d have a single folder to access and merge all the data from.
Is there any limitation on the number of files in a folder Power BI Desktop version can handle? The folder that I am working on will have 2 thousand files a year, but file size of each file is about 20 KB.
The only limitation is the amount of memory you must consume to load all the files. The Query Editor has load each file, parse it then merge it together to form a single table. The more files the more memory you will need to consume. When the load time becomes excessively long or starts failing, you will want to start thinking about a different process on how to take an entire year at a time and merge the files together into a single file. You might want to investigate this in dataflows, as I think you have some additional flexibility to only load recent files and append new data into the final table. https://docs.microsoft.com/en-us/power-bi/service-dataflows-overview
Thank you for sharing this… I am trying to read all files in folders and sub-folders of a drive; It was working earlier however I am not able to do it now, because of the length of file name in one of the folders. I don’t want to rename the folder. Could you please suggest any alternative on this.
I am not of a work around. I think you will need to shorten the file names or have less files nested in the folder structure. Consider flattening out your folder structure.
Hey, Thanks for the article. I have a business case where I need to connect Folder & pull all the files each month (Historical & new file which is saved every month). But now considering volume(GB) I need to keep historical data as it is & only load incremental data(New file from same folder). Is there any workaround?
If you are on Power BI premium you should be able to turn on incremental load for your data source. This would load only the new data into the data model and append it to previously load data. However, if you are loading gigs of data using folders I would recommend investing in a proper database, or looking into using Power BI dataflows. https://docs.microsoft.com/en-us/power-bi/service-dataflows-incremental-refresh
Quite helpful.. Thanks for the article